Horizontal Pod Autoscaling (HPA)
Last updated: June 10, 2026
| Tier | Deployment |
|
|
Introduction
IMPORTANT:
HPA can be enabled on self-managed deployments starting with version L2025.1 SP2.
Horizontal Pod Autoscaling (HPA) is a built-in Kubernetes mechanism that dynamically adjusts the number of pod replicas based on resource utilization, optimizing how available system resources are leveraged to efficiently handle current operations and tasks.
At a high level, the process can be described in the following steps:
-
Ongoing monitoring of resource consumption.
-
Evaluation of scaling actions against target metrics.
-
Scaling action – adjusting the number of pod replicas by scaling up or down.
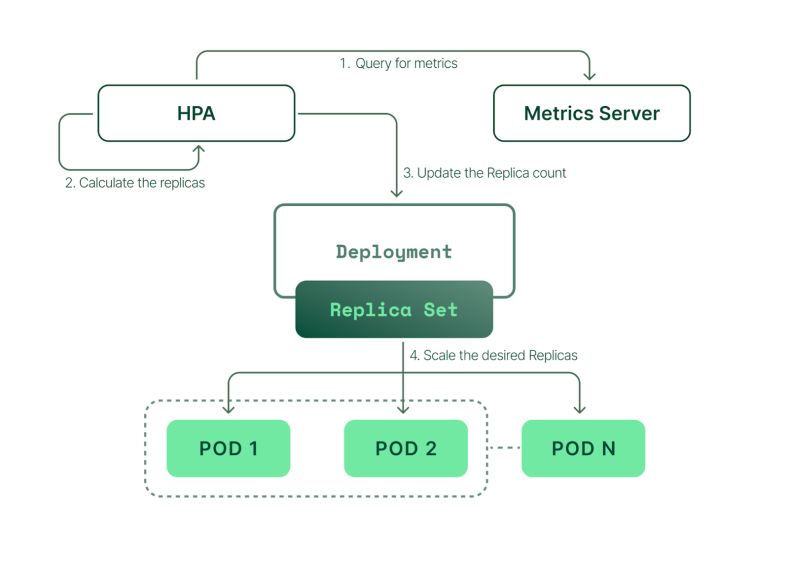
The core benefit of HPA is its ability to provide automatic scaling for Kubernetes microservices, ensuring optimal resource utilization based on real-time demand. By continuously monitoring resource usage, such as CPU and memory, HPA helps maintain application responsiveness during peak traffic while minimizing resource waste during periods of lower activity. This automated scaling improves application reliability, optimizes infrastructure costs, simplifies management, and enables organizations to efficiently handle fluctuating workloads without manual intervention.
For more information, see:
How HPA Works
Core Components
-
HorizontalPodAutoscaler - A Kubernetes API object that defines the scaling behavior for a specific workload. It specifies the target resource metrics and the desired range for the number of replicas, including conditions for scaling up or down, as well as minimum and maximum replica limits.
-
Metrics Provider - The source of metrics used by the system to determine whether pod replicas should be scaled up or down. This can be the native Kubernetes Metrics Adapter (Metrics Server) or a Custom Metrics Adapter.
-
Controller Manager - Runs the HPA controller, which periodically evaluates current resource utilization against the defined scaling thresholds and adjusts the number of replicas accordingly.
HPA in Sisense is based on CPU consumption as the primary resource metric for scaling decisions.
Supported Services
See Sisense services for a list of all services that support HPA.
Note:
Do not create scaling configuration files in services which are not included in the list. They are not certified by Sisense, and can lead to unpredictable behavior.
Configuration
Note:
In order to avoid overload, the query pod HPA settings should correlate with the number of EC-qry replicas.
HPA Settings
-
minReplicaCount- Defines the minimum number of pod replicas that must always be running. Even if workload demand is low, the system will not scale below this value to ensure baseline availability. -
maxReplicaCount- Defines the maximum number of pod replicas that HPA can scale up to. This prevents excessive scaling, ensuring that resource usage and costs remain controlled. -
stabilizationWindowSeconds- Specifies the cooldown period (in seconds) that HPA waits before applying another scaling action. This prevents rapid fluctuations (scaling up and down too frequently), ensuring stable operations. -
pollingInterval- Determines how often (in seconds) HPA checks resource metrics (e.g., CPU, memory) to decide whether scaling is needed. Frequent polling provides more responsive scaling but may increase system overhead. -
scaleUpPercent- Defines the CPU utilization threshold that triggers the Horizontal Pod Autoscaler (HPA) to scale up pod replicas.
The following example shows how these settings work together:
autoscaling:
minReplicaCount: 2
maxReplicaCount: 20
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 700-
The system starts with at least 2 pods and can scale up to 20 pods.
-
HPA checks resource usage every 30 seconds (
pollingInterval). -
When the average CPU utilization of pods reaches 700% (0.7 CPU, or 70% of a single CPU core), HPA recognizes increased demand and triggers scaling actions.
-
Scaling up/down actions will not occur more frequently than every 5 minutes (
stabilizationWindowSeconds) to prevent instability.
Sample Configuration
The configuration is mostly common to all supported services and has different values depending on whether it is a single or multi node deployment type.
## Sisense chart extra values
## Single node sample:
service:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 10
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 700
## Multi node sample:
service:
autoscaling:
minReplicaCount: 2
maxReplicaCount: 30
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 700For the following services, the configuration differs from the common configuration:
Important Note:
It is strongly recommended to use the Sisense default configuration, as it provides certified, optimized, and constantly improved settings for optimal performance.
exporter-xlsx:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 30
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 700
nlq-compile:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 20
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 5600
nlq-rt:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 20
stabilizationWindowSeconds: 300
pollingInterval: 30
## depending on the deployment size - small or large (cluster_config.yaml)
small:
scaleUpPercent: 2100
large:
scaleUpPercent: 3500
query:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 20
stabilizationWindowSeconds: 300
pollingInterval: 30
## depending on the deployment size - small or large (cluster_config.yaml)
large:
scaleUpPercent: 3500
small:
scaleUpPercent: 2100
translation:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 20
stabilizationWindowSeconds: 300
pollingInterval: 30
## depending on the deployment size - small or large (cluster_config.yaml)
large:
scaleUpPercent: 3500
small:
scaleUpPercent: 2100Enablement
Note:
When installing Sisense using Provisioner and Helm, you can also configure the installer-values.hpa.enabled HPA parameter to true or false (default: false).
To enable HPA on your deployment:
-
Enable HPA in the yaml configuration file (i.e., single_config.yaml, cluster_config.yaml etc.): set
hpa.enabledtotrue. -
Modify the HPA Settings:
Sisense has a default configuration that is continuously tuned based on performance insights and feedback from all Managed Cloud customers. If the configuration in the deployment file is left empty, the default settings will be applied automatically.
Important Note:
It is strongly recommended to use the Sisense default configuration, as it provides certified, optimized, and constantly improved settings for optimal performance.
However, if you need to override the default configuration, you can do so by updating the /installer/extra_values/helm/sisense.yml file in the extra_values folder for each service.
For example, in Galaxy, you can configure it as follows:
-
Single node:
Copygalaxy:
autoscaling:
minReplicaCount: 1
maxReplicaCount: 10
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 700
-
Multi node:
Copygalaxy:
autoscaling:
minReplicaCount: 2
maxMultiReplicaCount: 30
stabilizationWindowSeconds: 300
pollingInterval: 30
scaleUpPercent: 700
-
Verifying the Deployment
Check that the HPA has been created and is functioning correctly:
kubectl -n sisense get hpa
kubectl -n sisense describe hpa <hpa-name>[sisense]$ kubectl -n sisense get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
analyticalengine-hpa Deployment/analyticalengine cpu: 1%/700% 2 30 2 47h
api-gateway-hpa Deployment/api-gateway cpu: 5%/700% 2 30 2 47h
configuration-hpa Deployment/configuration cpu: 19%/700% 2 30 2 47h
exporter-xlsx-hpa Deployment/exporter-xlsx cpu: 33%/700% 1 30 1 47h
exporting-hpa Deployment/exporting cpu: 1%/700% 2 30 2 47h
galaxy-hpa Deployment/galaxy cpu: 1%/700% 2 30 2 47h
identity-hpa Deployment/identity cpu: 1%/700% 2 30 2 47h
model-graphql-hpa Deployment/model-graphql cpu: 1%/700% 2 30 2 47h
oxygen-hpa Deployment/oxygen cpu: 1%/700% 2 30 2 47h
pivot2-be-hpa Deployment/pivot2-be cpu: 1%/700% 2 30 2 47h
query-hpa Deployment/query cpu: 2%/2100% 2 30 2 47h
reporting-hpa Deployment/reporting cpu: 1%/700% 2 30 2 47h
translation-hpa Deployment/translation cpu: 2%/2100% 2 30 2 47hTuning Recommendations
A prerequisite for optimization of the existing configuration is establishing reliable means of monitoring. The suggested monitoring tool is Grafana. Sisense provides already preset dashboards that can be used to adjust the configuration. It is also possible to use official HPA Grafana dashboards.
Note:
If the current configuration is not suitable for your needs or you observe unexpected behavior, Sisense recommends that you open a ticket with Support so that the official default configuration can be adjusted. This ensures that certified and supported settings will be used.
FAQ
HPA is enabled by default on the Sisense Managed Cloud and is managed by Sisense Cloud team.
For self-hosted deployments we recommend having it enabled and using the default configuration by keeping the/installer/extra_values/helm/sisense.yml file empty in the extra_values folder . You can validate the decision based on CPU consumption in the performance metrics. For more information, see Using Grafana to Troubleshoot Performance Issues.
No. Although commonly utilized in AWS environments, Sisense's HPA implementation is cloud-agnostic and works seamlessly across all Kubernetes-supported environments. For detailed information on supported environments and configurations, refer to Sisense's Minimum Requirements for Linux Environments.
Data Groups in Sisense enables administrators to allocate and manage resources for ETL and querying of ElastiCubes by grouping them based on priority, usage patterns, or other criteria. HPA operates at the application level, automatically adjusting the number of pod replicas based on real-time metrics. It is suggested to balance properly to prevent bottlenecks when querying is autoscaled, but data groups settings are limited. For more details on configuring Data Groups, see Creating Data Groups.
It is for both. We suggest using the default configuration which dynamically defines scale for single and multi node deployments.
horizontalPodAutoscalerConfig has the policy which defines when the amount of pod replicas should be scaled up and down. The Cloud team constantly monitors and tunes the configuration for the best results. There is no action needed from the customer. If unexpected behavior is observed, create a ticket for the Support team.
HPA configuration is established on the helm chart level used for the deployment. Therefore, there is no publicly available config that can be changed in real time.
Side by side upgrades do not override the new HPA configuration, as it can be changed only via extra_values/helm configuration.
No. Sisense autoscaling is implemented and certified with the native Kubernetes Horizontal Pod Autoscaler (HPA) only, based on CPU consumption. KEDA ScaledObjects and other custom autoscaling mechanisms are not supported and may lead to unpredictable behavior. For the list of services that support HPA, see Sisense Linux Services.