Data Source Connection Management
Last updated: June 10, 2026
| Tier | Deployment |
|
|
|
Key Concepts
For Sisense to retrieve data from a data source, you must create a connection between Sisense and the data source.
Note the following terms:
-
Connector - A connector is a standalone software or function used to connect any application to a database system. A connector has the information required to connect to a particular data source type. Multiple connections can be based on each connector.
-
Connection - A connection is based on a connector and the information required to connect to a specific data source instance. The instance information required is the data source's:
-
URL (connection string)
- Credentials
-
Introduction to Connection Management
Connection Management enables efficient management and governance of all data connections in one place. It enables seamless connectivity between Sisense and various data sources, ensuring that connections are reusable, secure, and sharable across multiple assets such as ElastiCubes, Live Models, and Notebooks.
Traditionally, each data model required its own separate connection, leading to potential duplication, difficulty in governance, and manual updates. With Connection Management, this process is streamlined by allowing a single connection to be shared and reused across different models and assets, reducing redundancy and ensuring consistency.
From a technical perspective, Connection Management acts as a repository for all connections. Each connection is treated as an atomic entity within the system, identified by its own OID (Object Identifier), which remains consistent across different environments - just like Data Models or Dashboards.
Key Use Cases
-
Reuse Across Multiple Assets: A single connection can be reused across multiple data models and asset types (ElastiCubes, Live Models, Notebooks), streamlining connection management.
-
Secure Sharing: Connections can be shared without the need to expose sensitive data, such as login credentials or passwords, ensuring security across teams and users.
-
Centralized Management: Centralized management and governance enable administrators to control and monitor all connections from a single location, simplifying oversight.
-
Instant Updates: Any changes made to a connection are instantly applied to all dependent assets, eliminating the need for manual updates and ensuring consistency across the system.
-
Encourages Connection Sharing: The system encourages the sharing of existing connections to reduce duplication and maintain a streamlined connection structure.
-
Visibility and Dependency Management: Gain visibility into all assets that depend on a connection, with the ability to manage dependencies, ensuring that any connection changes are carefully handled.
Since the release of Sisense version L2024.3, Connection Management has become the unified and single solution for managing all connections to data sources in Sisense.
Creating New Connections
Creating a connection is an integrated step within the asset creation wizard - whether you are designing a Notebook, ElastiCube, or Live Data model. During the creation process, you can either choose an existing connection that is available to you or create a new one.
To create a new connection:
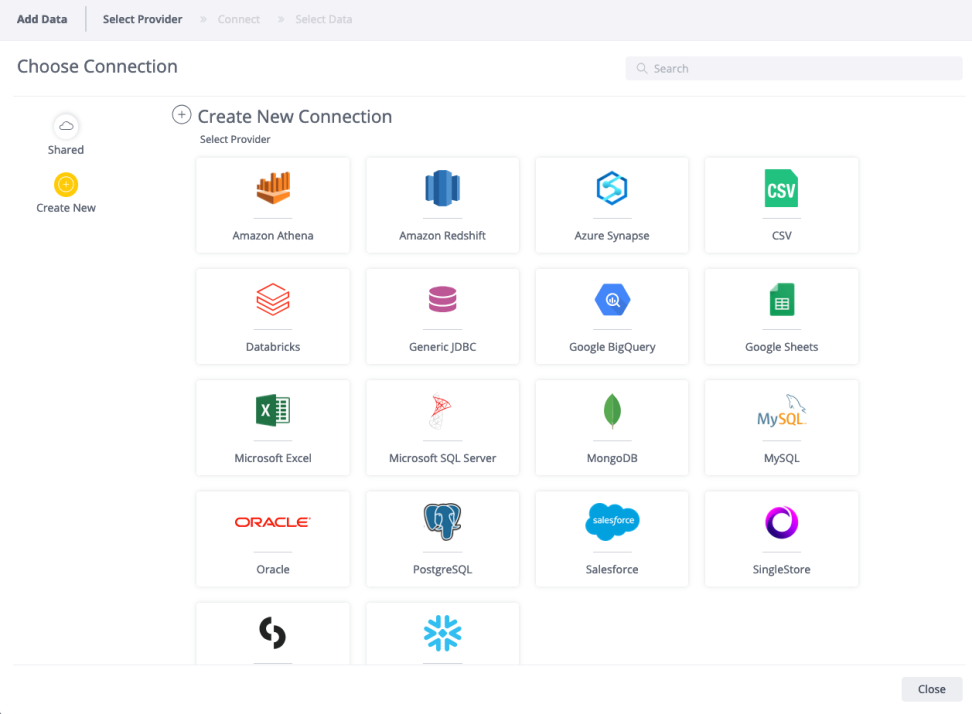
- From the Data tab, click Connection Management. A list of existing connections appear.
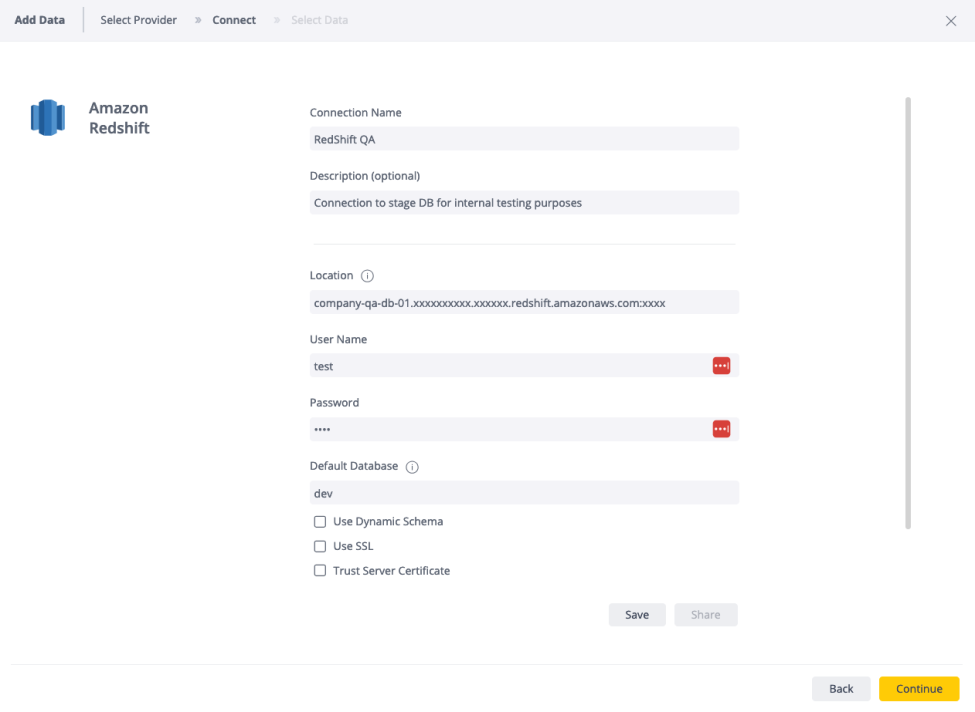
- Click + Connection. The Add Connection screen appears:
-
Select the desired data source provider.
-
Fill in the required details, such as the connection name, user name, and password.
Testing of the connection is part of the Save/Continue validation process to ensure that the connection details are correct and functional before proceeding.
Creating new connections is available for roles higher than Designer > Admin, Data Admin, and Data Designer.
Sharing Connections
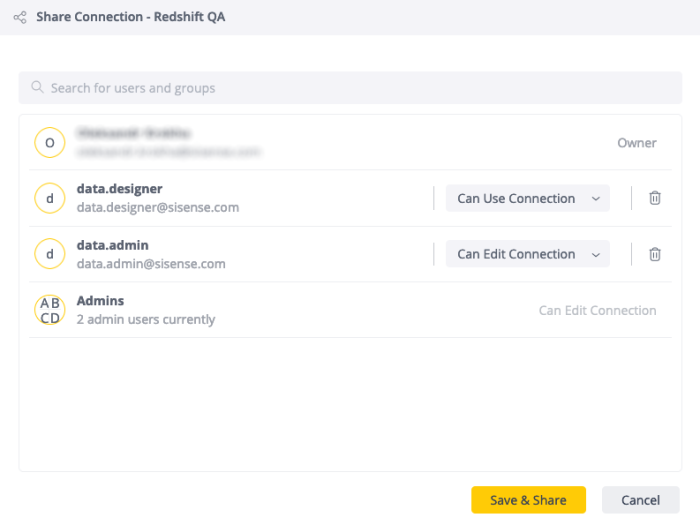
Connections can be shared during the creation flow or afterward. To share a connection while creating it:
-
Once it is saved, click Share.
-
Select the user or group with whom you want to share the connection.
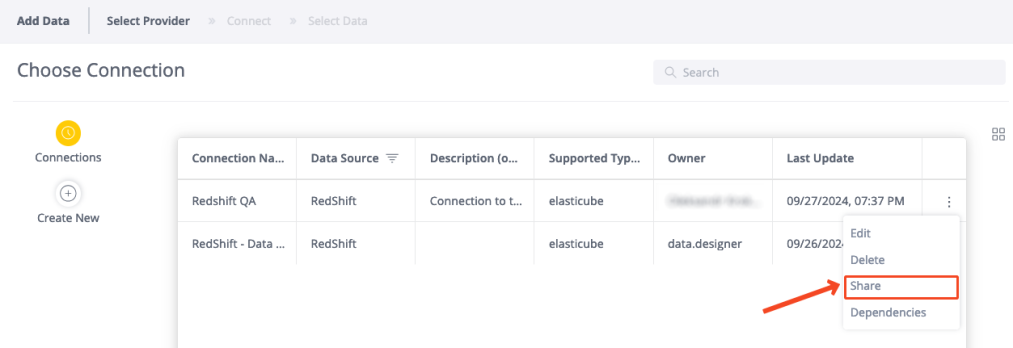
For existing connections:
-
Find the connection in the list.
-
Click the 3-dot context menu and select Share.
Connections can be shared with the following permission levels:
-
Can Use Connection: Allows the user to use the connection for creating data assets, but without access to credentials
-
Can Edit Connection: Allows the user to edit the connection details
Admin and Data Admin roles can share any connection within the instance, while Data Designers can only share connections they own.
From a technical perspective, connections have four types of permissions:
-
OWNER: Defines the owner of the connection
-
EDIT: Enables editing of any connection details
-
USE: Allows users to create data assets based on the connection, without having access to the credentials
-
READ: Granted by default to all users, enabling them to read data from assets such as dashboards and widgets
To unshare a connection, open the Share window, find the user in the list, and click the trashcan icon to remove their access.
Note:
Sharing a connection in the Notebooks tab is currently not supported and should be performed using the PATCH/connections/{connectionId}/shares/update endpoint.
Editing Connections
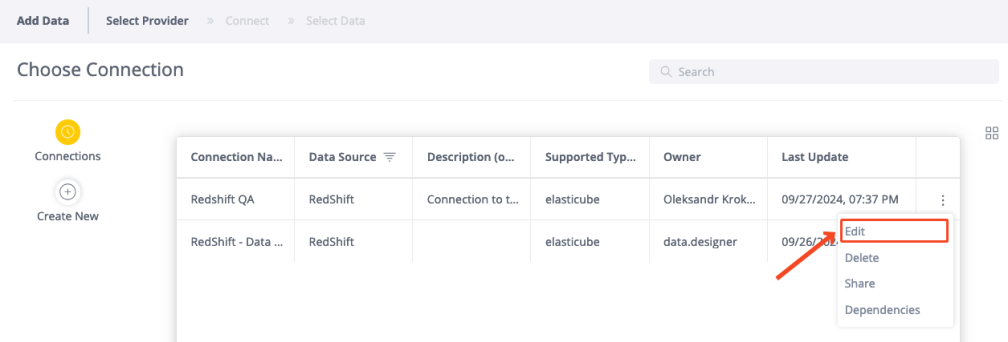
To edit an existing connection:
-
Find the connection in the list.
-
Click the 3-dot context menu and select Edit.
Important:
-
Any changes made to a connection are instantly applied to all assets dependent on it, such as Notebooks, ElastiCubes, or Live Data models. Ensure that the updates will not disrupt any assets using the connection.
-
Saving an edited connection requires testing it, which is included out-of-the-box when clicking Save.
Checking Dependencies
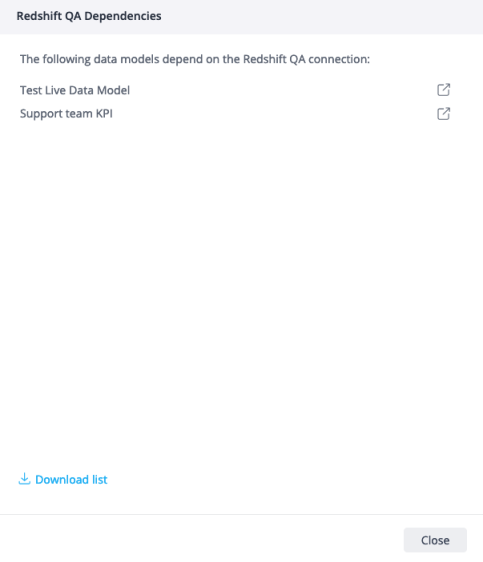
To see which assets are using a particular connection:
-
Click the 3-dot context menu of the connection and select Dependencies.
A list of data models that depend on the connection is displayed.
-
If the list of dependent assets is too large, or if you need a complete array of all dependencies, click Download list.
Note:
Always check the dependencies before editing or deleting a connection to avoid unintended disruptions to assets such as Notebooks, ElastiCubes, or Live Data models.
Deleting Connections
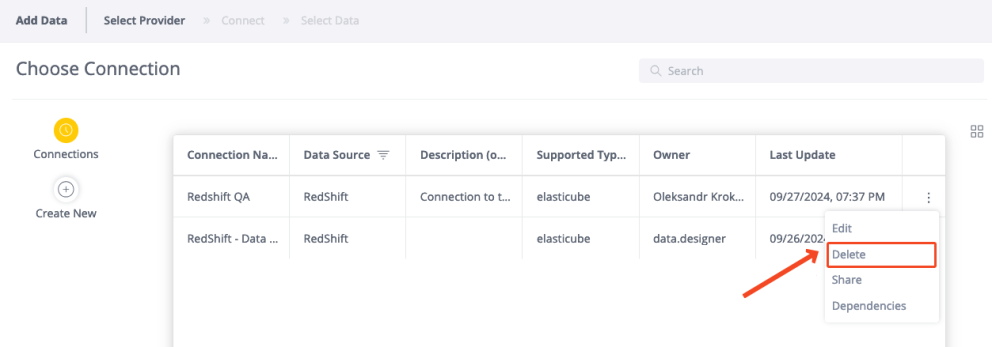
To delete a connection:
-
Select the connection from the list.
-
Click the 3-dot context menu of the connection and select Delete.
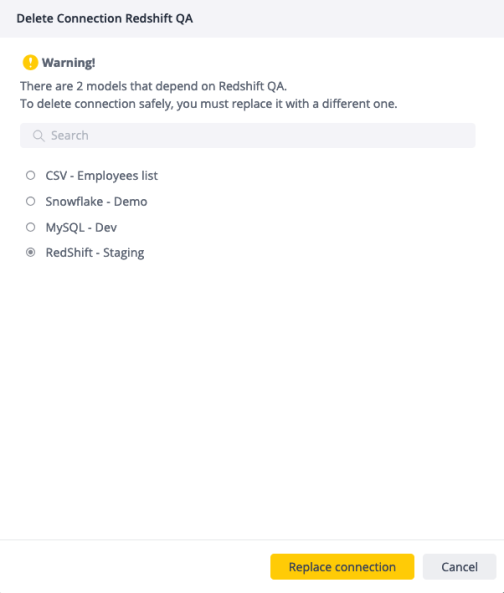
If there are assets that depend on the connection, you must select a new connection to replace it before proceeding.
Note:
Once a connection is deleted, it cannot be restored, and all dependent assets will be affected. Ensure you check the dependencies beforehand to prevent unintended disruptions to assets like Notebooks, ElastiCubes, or Live Data models.
Connection Utilization Scope
While we aim to minimize duplicated connections, there are some limitations due to differences in connection structure between Notebooks and data models:
-
Connections created in Notebooks: As Notebooks require a “Default Database” and also have ability to create a new data model directly from the Notebooks, connections created from Notebooks will have "supportedModelTypes": [ "NOTEBOOK", "EXTRACT", "LIVE" ]. At the same time, when removing the “Default Database” from the connection which is used in the Notebook, users will receive an error requiring them to exclude Notebooks from the list of supported model types first.
-
Connections created in Data Models: These connections can be used in both ElastiCubes and Live Data models, provided the connector is supported in Live Data models (e.g., CSV is not compatible with Live Data models)
From a technical perspective, the accessibility of a connection for a specific asset type is defined by the “supportedModelTypes” parameter. The available options are:
-
EXTRACT > ElastiCube
-
LIVE > Live Data Model
-
NOTEBOOK > Notebook
To modify the default permissions, for example, limiting the connection to ElastiCubes only, you can use the PATCH /connections/{connectionId} endpoint.
Multitenancy Considerations
Connections are isolated within the tenant they are created from and cannot be accessed by users from other tenants.
Accessing and Managing Available Connections
Note:
B2D connections are isolated from Connection Management. You must use dedicated B2D connections for this.
Connections as Part of the New Data Model Wizard
To view all available connections, navigate to the new data model creation wizard by clicking  from within the data model. For more detailed information about each connection, such as its description and creation date, switch to the List view using the toggle in the top-right corner.
from within the data model. For more detailed information about each connection, such as its description and creation date, switch to the List view using the toggle in the top-right corner.
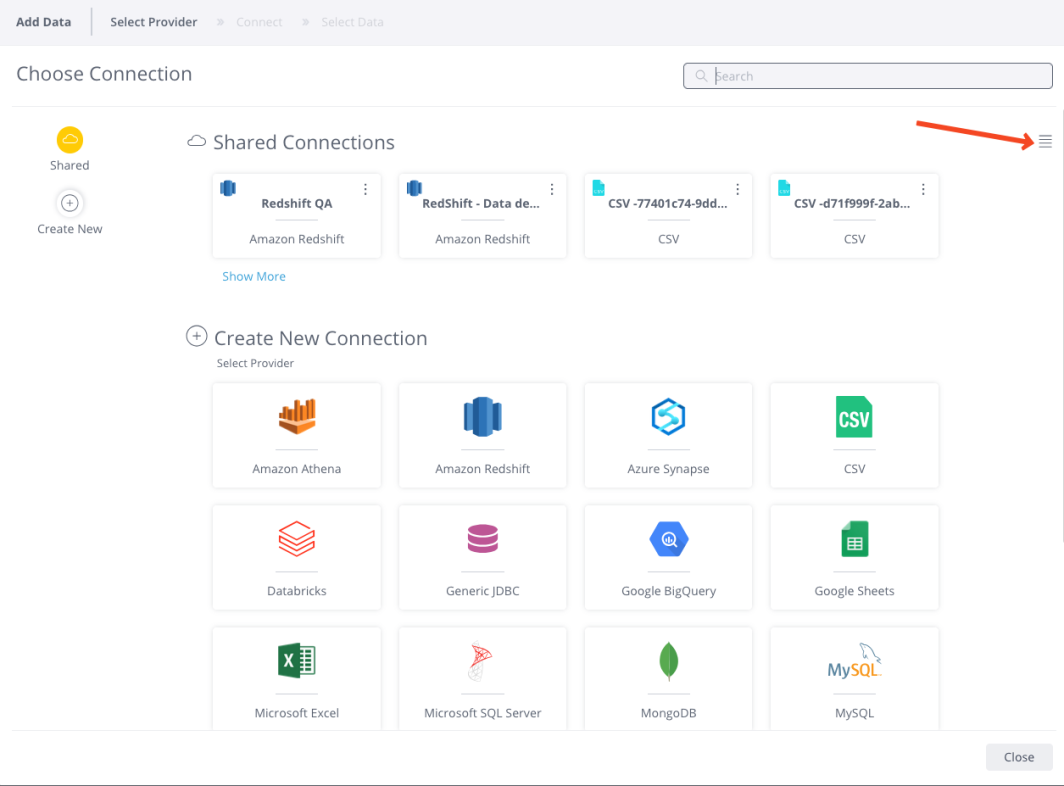
The List view also enables filtering and sorting of connections for easier management.

Roles:
-
Admins and Data Admins: Can view all connections within their tenant scope
-
Data Designers: Can only view connections they own or those shared with them
Centralized Connections List in the Data Tab
Connections available to users are accessible via a dedicated page under the Data tab.

This centralized list provides a convenient way to browse and manage all data source connections available in the instance, respecting the user's RBAC and sharing permissions.
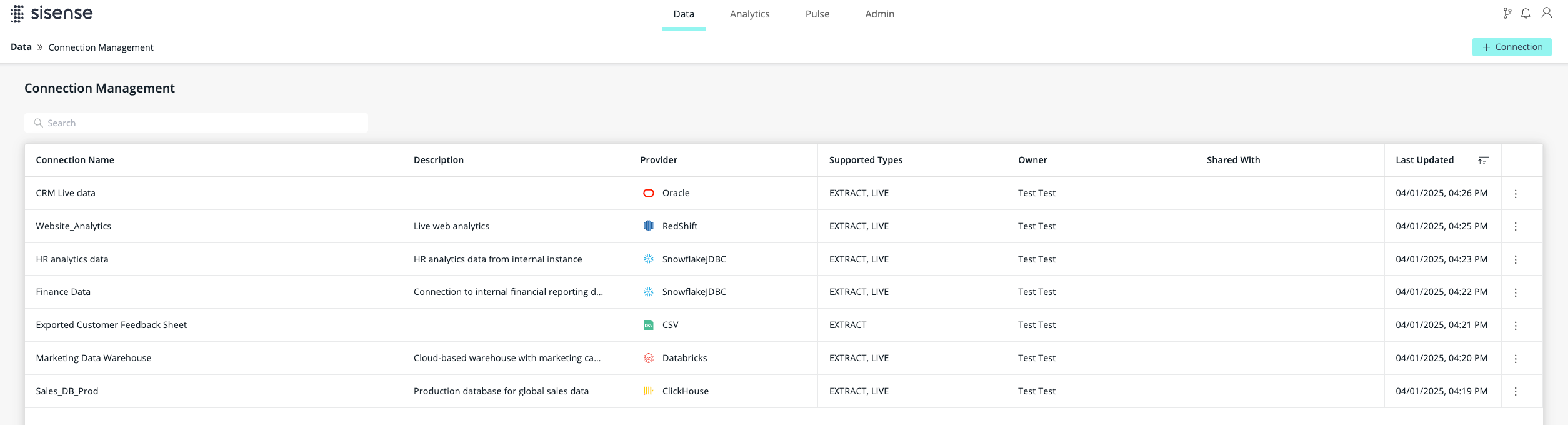
In addition to standard options such as search, sorting, and column filtering, each connection includes an options menu (" ") for additional actions such as sharing, editing, viewing dependent assets, and deleting the connection. The operations available from this centralized view are consistent with those available in the Data Model Wizard.
") for additional actions such as sharing, editing, viewing dependent assets, and deleting the connection. The operations available from this centralized view are consistent with those available in the Data Model Wizard.
Importing Connections to the System
Currently, there is no dedicated option to export connections individually, such as Perspectives or Data Security. However, connections can still be imported into the system via two main methods: Importing Data Models and Promoting via Git Integration.
Importing Data Models
When a data model is exported, the connection parameters are encrypted and included as part of the exported .smodel or .sdata files. Upon importing the data model back into the system, these connection parameters are automatically converted into a managed connection, unless a connection with the same OID, or the same connection parameters scope owned by the user, already exists in the instance.
Important:
If the imported data model contains a modified connection with an OID that already exists in the system, the existing connection will remain unaffected. The system will simply fetch the current connection details from the database using the OID from the data model.
-
Each base table is associated with a connection, and the connection object will always be populated. For models created in recent years, the connection object also includes the connection OID.
-
When attempting to import a connection from an .smodel, the system first checks for an existing connection by the OID. If found, the connection object is ignored, even if the parameters differ.
-
If no matching connection is found by OID, the system will serialize the connection parameters and search for an identical connection (e.g., the same connection string, credentials, and other parameters) owned by the user performing the import. If found, the new connection will replace the connection from the original imported data model. This prevents the creation of unnecessary duplicated connections.
-
If all attempts to find an existing connection fail, a new connection is created using the connection parameters from the .smodel.
Example:
If an exported data model has a connection with OID 123 based on the connection string jdbc:snowflake:ABC, but the connection string was later changed to jdbc:snowflake:DEF, upon importing the data model, the system will use the current connection details from the database (i.e., jdbc:snowflake:DEF), not the one from the imported data model.
The ability to duplicate connections during the import of data models will be introduced in a future release.
Git Integration Promotion
When pulling a data model from a remote repository, such as GitHub or Azure, into the system, an empty connection is generated, unless a connection with the same OID already exists in the instance.
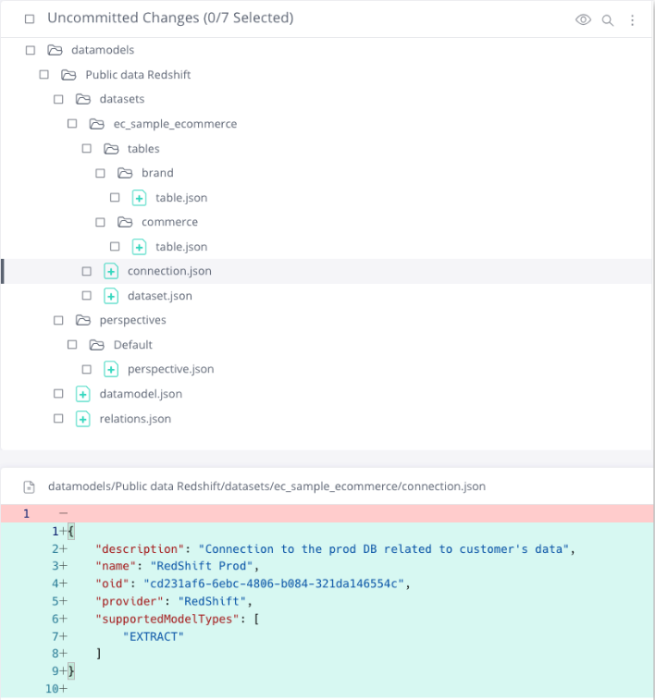
Since sensitive data like connection parameters are excluded from tracked files in the Git project, for the data model to function properly, you must update the connection with the relevant credentials under the static connection OID.
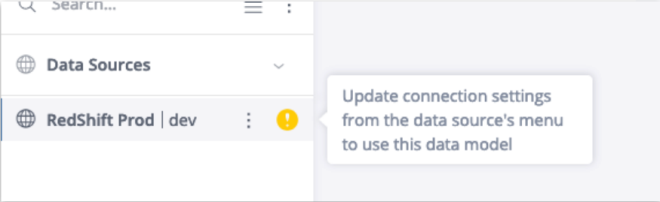
For example:
Dev Server:
-
Data Model: Sample E-Commerce
-
Connection OID: 123
-
User: Developer
-
Password: xxxxxx
Stage Server:
-
Data Model: Sample E-Commerce
-
Connection OID: 123
-
User: QA
-
Password: xxxxxx
Prod Server:
-
Data Model: Sample E-Commerce
-
Connection OID: 123
-
User: Admin
-
Password: xxxxxx
This way, the same data model will use the same connection OID across environments, while pointing to the appropriate database for each environment.
Note:
To prevent merge conflicts and simplify the flow, for Git imported data models, the option to switch connections is disabled. You can only update the imported one. Once it is updated, all of the options are the same as in regular data models, including switching.
API Endpoints
Endpoints to work with the feature > 2.0 Connections Management:
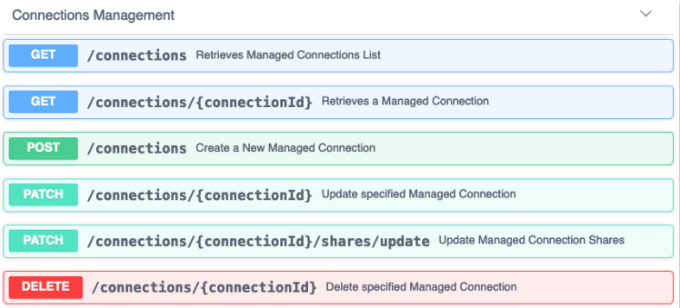
-
GET: retrieves connection
-
all connections
-
single connection
-
-
POST: creates new connection
-
connector’s manifest can be accessed in developer.sisense.com
-
-
PATCH: updates existing connection
-
updating full connection or specific properties
-
adjust shares - grant/revoke access
-
-
DELETE: removes connection
-
has validation on the dependencies, which must be addressed in the UI
-
dedicated endpoints for retrieving dependencies and replacing connection planned for latter phases
-
Enablement and Migration
Starting with Sisense version L2024.3 and newer, Connection Management becomes the unified and standard solution for managing connections to data sources for all customers. It is enabled by default, and cannot be disabled. The migration to this new system is part of the system upgrade and involves several key steps:
-
Conversion of Old Connections: All legacy connections are converted into the new managed connections format.
-
Setting “supportedModelTypes”: The connection type is determined by the asset it was converted from:
-
NOTEBOOK: If the connection was converted from a Notebook
-
EXTRACT/LIVE: If the connection was converted from a Data Model
-
-
Deduplication of Connections: Keeping only unique connection aiming to prevent duplicates. If there were multiple connections with identical connection details but owned by different users, they are converted into two separate managed connections.
-
Ensuring Backward Compatibility: All assets that previously used these connections will continue to function seamlessly, maintaining full backward compatibility.
This migration process ensures a smooth transition to the new Connection Management system without disrupting existing workflows or assets.
Note:
Migration to Connection Management (CM) is included as part of the upgrade beginning with version L2024.3 SP2. The feature is only enabled if the migration completes successfully. If the migration fails, the system will continue using legacy connections.
If Connection Management is not enabled after the upgrade, check the Support Log Files for errors containing "ConnectionMigration" or contact Sisense Support by opening a ticket.
If you are migrating from Windows to Linux, you must first upgrade to a version older than L2024.3 SP2.
API and System Behavior Changes with Connection Management
Deprecated Endpoints
In 2020, these endpoints were removed from the public Swagger REST API documentation. However, some customers may have incorporated them in internal custom script-based solutions.

The most notable endpoints in this context are:
/api/internal/connection:
-
GET: Retrieve a list of all connections -
POST: Create a new connection
/api/internal/connection/{id}:
-
GET: Retrieve a single connection by ID -
PATCH: Update an existing connection -
DELETE: Delete a connection
Due to significant changes in the connection structure, we have introduced a new API version specifically for managing new managed connections. These new endpoints are outlined in the API Endpoints section above.
The legacy endpoints will now return a 410 Gone HTTP error with the following message:
"This connection endpoint has been deprecated and is no longer available. Please use the new Connections Management API endpoints."
Changes in Internal Private api/v2/ecm GraphQL Payloads
The api/v2/ecm endpoint is a backend implementation responsible for handling all GraphQL queries, mutations, and subscriptions used by the Sisense Data Tab application.
This endpoint is not part of the public API and is excluded from the Swagger REST API documentation. Despite this, some customers might have integrated these endpoints into their own scripts.
To maintain backward compatibility for these unsupported use cases, we have ensured that mutation inputs and types (outputs) retain their structure to avoid breaking changes.
-
New Optional Properties Added:
name,description,supportedModelTypes,lastModified, andconnectionPermissions. -
Changed Properties:
providerandparametersare now optional instead of mandatory.
As a result, the GraphQL validator no longer strictly enforces input types.
Important Note:
If you are using mutations such as addDatasetToElasticube, and provide incomplete connection parameters, you may encounter unstable connections or inconsistent data models.
While we have taken measures to prevent breaking changes, this endpoint remains unsupported for external use. For reliable and stable integrations, always use the documented and supported public APIs.
Breaking Changes in the GET api/v2/datamodels Endpoints
A key objective of Connection Management is to enhance security by addressing the issue of connection parameters being exposed (protected fields are encrypted) and returned in various /api/v2/datamodels endpoints.
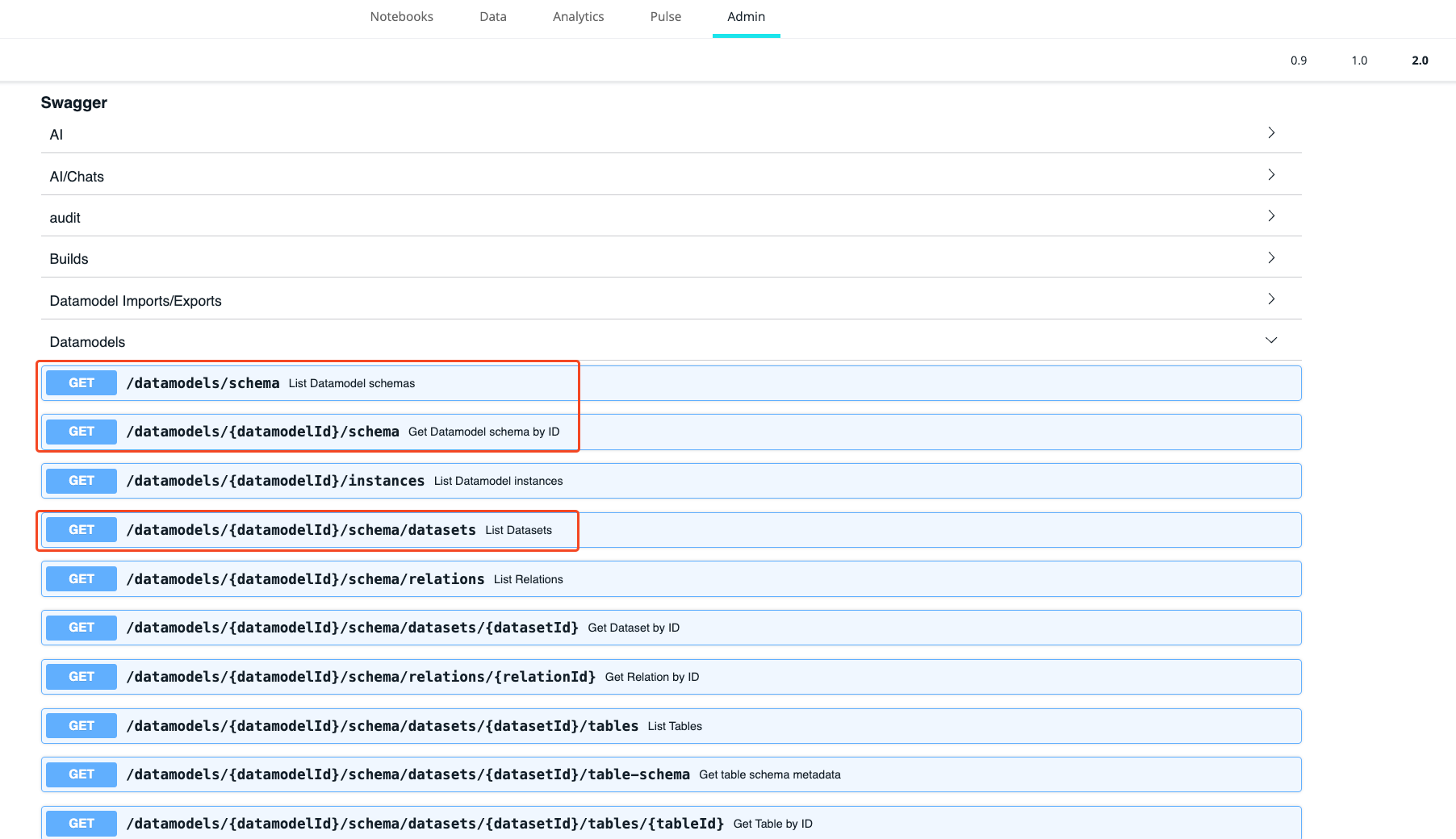
Currently, this endpoint continues to return the full connection structure with all property values intact. However, starting from Q2 2025 (L2025.2), all properties, except for oid and provider , will be set to null. This transitional period is intended to enable customers to update their custom script-based solutions, if there are any.
The following is an example of how the payload will appear after the deprecation takes place.
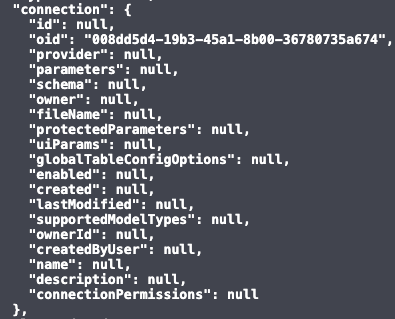
The /api/v2/datamodel-exports/schema endpoint remains unchanged (as it was before) and can be used if you need to export the full data model, including encrypted connection parameters.
Measures to be taken:
If you use one of the following endpoints in your custom implementations:
-
GET /api/v2/datamodels/schema -
GET /api/v2/datamodels/(.*)/schema -
GET /api/v2/datamodels/(.*)/schema/datasets
make sure to switch to GET api/v2/datamodel-exports/schema or use new dedicated 2.0 Connections Management endpoints.
Summary and Key Updates of the Flow Associated with Connection Management Enablement
-
New Shared Managed Connection is now the only unified solution for connecting to the data source.
-
Deprecation of
/api/internal/connection&/api/internal/connection/{.*}endpoints -
Differences between
/api/v2/datamodelsand/api/v2/datamodel-exports/schema:-
The
/api/v2/datamodelsendpoint currently returns the full connection structure, including all property values, for backward compatibility. However, starting with Q2 2025 (L2025.2), all properties, except foroidandprovider, will be set tonull. -
The
/api/v2/datamodel-exports/schemaendpoint still returns connection parameters, as previously, and is not affected by the connection management.
-
-
New Connection Management Endpoints: The
/api/v2/connectionsendpoints are now used for managing connections -
Connections are now shared: Editing a connection will affect all data models that use the same connection
-
Connection Deletion: Deletion is only possible if there are no dependent assets relying on the connection