Connecting to Google BigQuery
Last updated: June 10, 2026
| Tier | Deployment |
|
|
|
Note:
This topic describes how to import data into Sisense's ElastiCube, and how to use Introducing Live Models.
Sisense's Google BigQuery connector is a powerful tool that enables you to retrieve from BigQuery only the data that
you require, based on timestamp, date range or other parameters defined by you. This reduces import times and the
costs associated with querying a large number of tables in BigQuery.
You can import your data into a Sisense ElastiCube , or connect your data to a Sisense Live model, using
Introducing Live Models.
Note:
Make sure that you have the appropriate permissions to access your BigQuery dataset. For more information, see here.
Importing Into a Sisense ElastiCube
Sisense's Google BigQuery connector supports complex data types and partition types used in BigQuery. You can run queries on defined partitions, including tables partitioned by date field, sharded tables, and tables partitioned by ingestion time. Complex data types, including Nested and Nested Repeated, are ingested automatically without any need to write SQL or functions.
Authentication
When connecting to Google Big Query, you can choose the preferred authentication mechanism: OAuth or Service
Account. A service account is a Google account associated with your GCP (Google Cloud Platform) project. Use a
service account to access the BigQuery API if your application can run jobs associated with service credentials rather
than end-user credentials. For more details, click here.
BigQuery Storage API
Optionally, the connector allows using the Big Query Storage API. BQ Storage API is a paid Big Query service
that allows for additional parallelism among multiple consumers for a set of results. This way it enables the driver
to handle large result sets more efficiently. For details, see here.
Note:
For the list of supported connectors, see Data Source Connectors.
Adding a Connection to Google BigQuery
Sisense enables easy and quick access to databases, tables and views contained within Google BigQuery.
To connect to your Google BigQuery database, you need to provide a Project ID. The Project ID is a unique
identifier for your BigQuery project. You receive the Project ID when you create a project in Google BigQuery.
If you have already created a project and cannot find the Project ID, click here for help.
After you provide the Project ID, you can sign into your BigQuery account with your Google credentials. Once Google has authenticated your account, you can select what tables are to be imported into Sisense.
Note:
If you are connecting to a Google service remotely (for example, if you are on a Linux deployment), and the address of Sisense is something other than localhost, Google requires that you connect using the OAuth 2.0 protocol. See Google Authentication in Linux for more information.
To import Google BigQuery data:
- In the Data page, open an ElastiCube or click
 to create a new ElastiCube.
to create a new ElastiCube. -
In the Model Editor, click
 . The Choose Connector window is displayed.
. The Choose Connector window is displayed.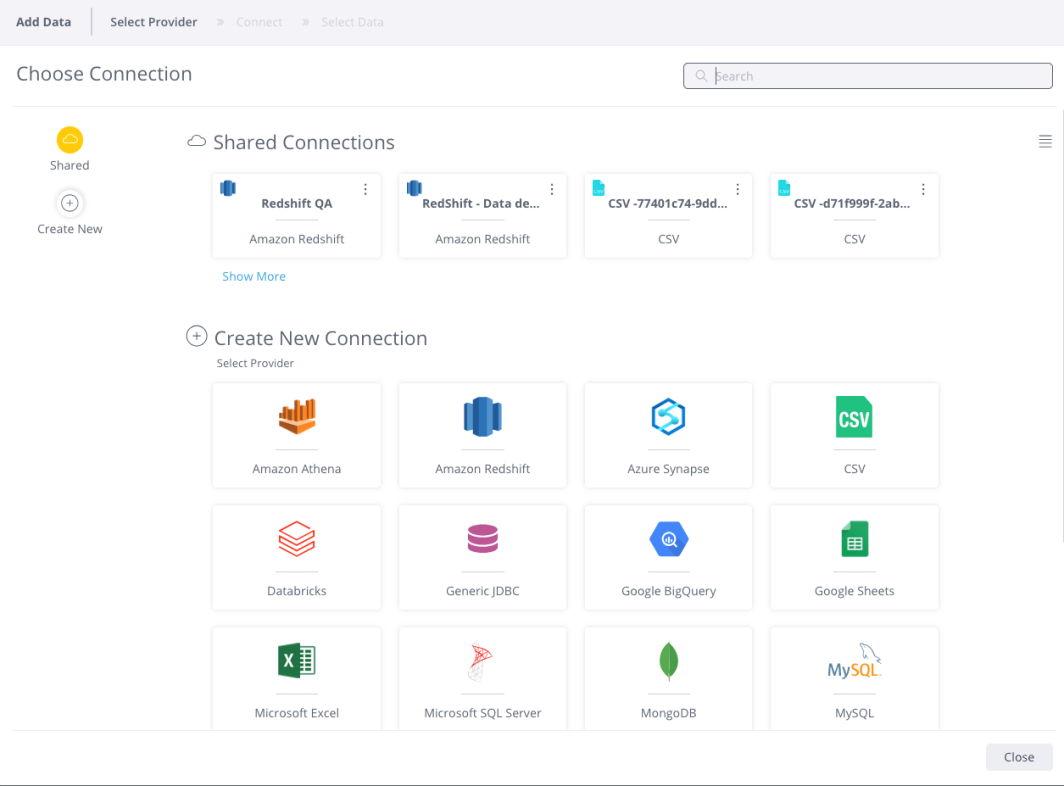
-
Choose an available managed connection, or create a new connection, for Google BigQuery. The Google BigQuery area is displayed.
- If your preferred authentication method is OAuth, click Sign in with Google and enter your email, and then select Next to enter your password. If you have multiple accounts, select the account that has the Google BigQuery data you want to access and enter the password, if you are not already signed in. You must be signed out of all other Google accounts.
- Click Accept to allow your Sisense Server to access your Google BigQuery data.
- In Project ID for Authentication, enter your BigQuery Project ID. This project ID is only used
for authentication. Once you log in, you will have access to all the projects to which you have Google Big Query
permissions.
If you have already created a project and cannot find the Project ID, click here for help. - Close the browser window when notified to do so.
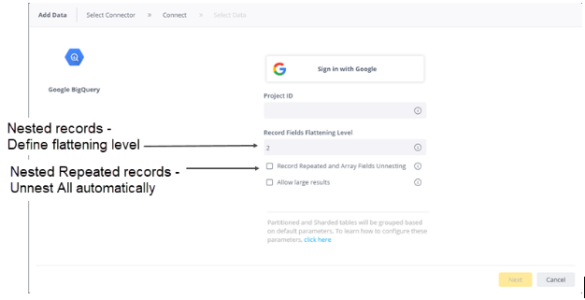
- In Record Fields Flattening Level, enter the number of nested levels you want to flatten. For example, in a table with nested data depth of seven, you may choose to flatten only the first two levels. The data on the other levels will not be imported into Sisense. See Connecting to Google BigQuery for more information.
- Select Record Repeated and Array Fields Unnesting if you want to unnest arrays and Nested Repeated fields, and to
flatten and unnest arrays of Records into additional rows. If you do not select the checkbox, all these data types
will be imported as strings.
-
Click Allow Large Results if your BigQuery query result is larger than 128 MB. When importing query results larger than 128 MB, BigQuery creates a temporary table (see below, or click here for more information). For this table to be created, you must be granted the Bigquery.tables.create permission in BigQuery (click here for more information). If you do not have this permission, the query results will not be imported into Sisense. The message that Sisense issues in this case is "Response too large to return. Consider setting allowLargeResults to true in your job configuration."
Notes about Temporary Tables
-
The Sisense BigQuery connector creates temporary tables in BigQuery under a specified dataset. By default, temporary tables exist for 24 hours.
-
From Sisense Version L8.2.6SP (Linux), newly created temporary tables will be written to a hidden dataset named
_simba_jdbc(hidden datasets are not visible in the BigQuery Web UI). -
You can customize the behavior of the "allow large results" feature.
-
To change the location of the temporary tables, add the parameter
LargeResultDataset=<datasetName>to the Additional parameter field in the connection settings page. -
To change the expiration date of the dataset, add the parameter
LargeResultsDatasetExpirationTime=<expirationTime>to the additional parameters field in the connection settings page.<expirationTime>is in milliseconds. This dataset must have an expiration date, otherwise the temporary tables will not be deleted.
-
- You will need to manually delete temporary tables that were created prior to Sisense Version L8.2.6SP.
-
- If your preferred authentication method is Service Account, you will need to connect to BigQuery with a service
account and load the credentials from a JSON file to Sisense:
- Create and download the Service Account Key JSON file. For instructions,click here.
- Upload the Service Account Key JSON file to the Sisense server (you can save it to any directory).
- In Sisense, select Authenticate With Service Account.
- In a field that opens, enter the full path to the Service Account Key JSON file on the Sisense server.
/opt/sisense/storage/<prefix of the path on the Sisense server>
- Click Next. All tables and views associated with Google BigQuery are displayed.
- From the Tables list, select the relevant table or view you want to work with. You can click

next to the relevant table or view to see a preview of the data inside it.Note:
When selecting the tables or views, Connector Wizard displays all schemas from all projects accessed, not only the schemas from the project whose ID you provided for authentication.
- When you select the table or view, a new option is displayed at the bottom of the list, Add Import Query.
- (Optional) Click + to customize the data you want to import with SQL. See Custom Queries to Reduce the Amount of Imported Data above for more information.
- After you have selected all the relevant tables, click Done. The tables are added to your schema.
Temporary Tables: Known Issues
In Sisense versions below 8.2.1 (Windows), temporary tables do not expire by default. To change this behavior:
- Manually refresh the connection at the data source level by changing the connection in the Data tab. This applies an expiration date to temporary tables.
- In BigQuery, in the dataset of the building table, set Default table expiration to Other value than "Never". All newly created tables of any given dataset will inherit the dataset's expiration period.
Querying Partitions
Sisense's Google BigQuery connector provides the ability to run queries on defined partitions:
- Sharded tables - supports the ability to view the parent tables (grouped view, as wildcard Select statement) while running queries per the partitions as filters.
- Tables partitioned by date field - querying by partitions as out-of-the-box functionality, via filters and custom queries.
- Tables partitioned by ingestion time - using BigQuery SQL functions via custom queries.
Sisense provides a unique solution to rebuilding the parent table from its constituent sharded tables (grouped view). For this, Sisense provides an external file, where you can indicate the custom prefixes or regular expressions (Regex) by which to group the shared tables into one parent table.
To group the shared tables into a single parent table:
-
Open the prefixes.json file (you can open it in Notepad). This file is located in the following directory:
...ProgramData\Sisense\DataConnectors\JVMContainer\Connectors\GoogleBigQuery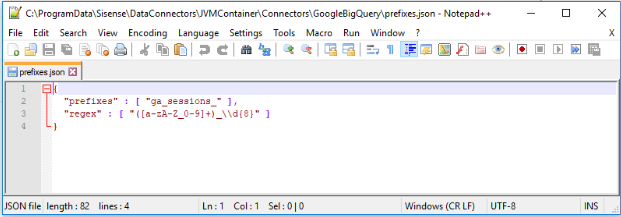
This file contains default prefix and Regex parameters that group all Google Analytics daily tables of the format "ga_sessions_YYYYMMDD" into one parent table.
-
To refine the grouping, modify the default parameters or add additional parameters as relevant to your data, and save the file. Make sure that the prefixes row is separated by a comma from the regex row.
-
To update your data model based on the new parameters, do one of the following:
- from the Connection Wizard, jump to a previous step and return to the step you were on.
- from the data model, open the Connector Wizard to add another table.
In both cases, The Connector Wizard will display the parent table, grouped from the sharded tables based on the indicated parameters.
Controlling the Partitions to Import with Custom Queries
Note:
This feature is available in Live data models starting from Sisense version 8.0.1. On earlier versions it is available only in ElastiCube data models.
Google BigQuery supports partitions and sharded tables to improve performance, availability, and maintainability.
The Sisense BigQuery connector provides the following abilities to run queries on BigQuery's table partitions and sharded tables:
- Partitioned tables : Tables that are partitioned based on a TIMESTAMP or DATE column. The Sisense BigQuery connector enables querying the partitions via filters and custom queries, simply by the where clause sent to BigQuery.
- Tables partitioned by ingestion time : Tables partitioned based on the data's ingestion (load) date or arrival date. The Sisense BigQuery connector enables using BigQuery SQL functions via custom queries to retrieve the requested partitions. Click here for details about these two methods.
- As an alternative to partitioned tables, Google BigQuery enables sharding tables using a time-based naming approach, such as [PREFIX]YYYYMMDD. This is referred to as date-sharded tables. See here for details. The Sisense BigQuery connector supports the ability to view the parent tables (grouped view, as Wildcard Select statement) while running queries per the partitions as filters.
You can import subsets of your partitioned and sharded tables into Sisense using SQL.
Note:
Starting from Sisense version 8.0.1, you can create custom SQL queries in Live data models. With Live table queries, you can now add and transform data and build custom business logic for analytics from Live models using custom SQL. Using this feature you can add a WHERE clause on your specific partition. For details, see Creating Custom Live Table Queries.
Querying Partitioned Tables
Tables partitioned based on a TIMESTAMP or DATE column do not have pseudo columns in BigQuery. To limit the number of
partitions scanned when querying partitioned tables, use a predicate filter (a WHERE clause).
A common use case of leveraging partitioned tables in BigQuery is the accumulate build. Defining the accumulate
build on a TIMESTAMP or DATE field enables you to scan only specific partitions, thus reducing the import times and
costs involved in querying in BigQuery.
For example, the following query prunes partitions:
SELECT
t1.name,
t2.category
FROM
table1 t1
INNER JOIN
table2 t2
ON t1.id_field = t2 field2
WHERE
t1.ts = CURRENT_TIMESTAMP()Querying Ingestion-time Partitioned Tables
When you create an ingestion-time partitioned table in BigQuery, two pseudo columns are added to the table: a
_PARTITIONTIME pseudo column and a _PARTITIONDATE pseudo column. The
_PARTITIONTIME pseudo column contains a date-based timestamp for data that is loaded into the table. The
_PARTITIONDATE pseudo column contains a date representation.
You can use the _PARTITIONTIME and _PARTITIONDATE pseudo columns to limit the number of
partitions scanned during a query. This reduces the on-demand analysis cost. For example, the following query scans
only the partitions between the dates January 1, 2019 and January 2, 2019 from the partitioned table:
SELECT
[COLUMN]
FROM
[DATASET].[TABLE]
WHERE
_PARTITIONDATE BETWEEN '2019-01-01'
AND '2019-01-02'See Query Partitioned Tables for a detailed explanation.
Querying Sharded Tables
BigQuery stores sharded tables in the format of table_name_SUFFIX (for example "ga_sessions_YYYYMMDD"). You can write a custom query to import only the sharded tables in the requested date range. This provides the benefit of faster and cheaper queries, since in BigQuery you pay for the amount of data you scan.
To do that, you can use wildcard tables combined with the _TABLE_SUFFIX pseudo column in the WHERE
clause. The _TABLE_SUFFIX pseudo column contains the values matched by the table wildcard. For example,
the following FROM clause uses the wildcard (* ) to match all tables in the ga_sessions dataset that
match a specific date.
SELECT
date,
SUM(totals.visits) AS visits,
SUM(totals.pageviews) AS pageviews,
FROM
`aerial-citron-207113.GA360.ga_sessions_*`
WHERE
_TABLE SUFFIX BETWEEN '20170801'
AND '20180801'
Group BY
date
ORDER BY
date ASC See When to use wildcard tables for a detailed explanation of the example.
Also, see BigQuery cookbook for additional examples of advanced custom queries.
Note:
Sisense uses the standard SQL dialect, and not legacy SQL (also known as the BigQuery SQL).
Querying Nested Objects
BigQuery supports nested records and arrays within tables. Nested records in BigQuery can be Single or Repeated records.
These record types are imported into Sisense as:
- Single records - as additional columns
- Repeated records - as additional columns and rows
Example: A BigQuery schema that has Single and Repeated records:
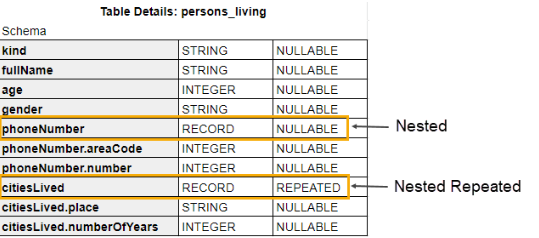
would be imported into Sisense as:

Click here for more information.
Sisense ingests both nested records and arrays automatically without any need to write SQL and functions:
- Nested data type : Flattens records/arrays to columns with the ability to choose how many levels to expand.
- Nested Repeated data type : Flattens repeated records to rows and columns automatically, using the UNNEST function.
Nested Objects
BigQuery supports Nested data as objects of Record data type.
When importing data into Sisense, you need to indicate how many levels of nested data you want to flatten (see Connecting to Google BigQuery). In Sisense, data on these levels will be flattened to columns using the dot operator (. ).
Data on the nested levels that you chose not to flatten is not imported into Sisense.
Array Objects
BigQuery supports Nested Repeated data as arrays of Repeated Record data type.
When importing data into Sisense, Nested Repeated data type is flattened to rows and columns automatically using the UNNEST function.
Note:
This feature is currently available only in ElastiCube data models. It will be available in Live data models starting from Sisense version 8.0. If you are on an earlier Sisense version and working with Live data models, you can use the UNNEST operator to retrieve nested and repeated data as flattened rows via custom query (see Work with arrays for more information).
Data in Array (primitive) data type is imported into Sisense. Sisense converts this data to un-indexed strings.
Source Limitations
- The following functions are not supported for Google BigQuery: Cot, Diff, Mod, Round
- The Storage API cannot be used with federated tables or logical views
- Maximum 15 nested levels (click here for details)
- Maximum query length: 1 MB
- Maximum response size: 128 MB compressed. This limitation can be overcome by clicking Allow Large Results Set as explained in Connecting to Google BigQuery .
- Query execution time limit: 6 hours
- Maximum number of tables referenced per query: 1,000
- Concurrent queries - based on the account rate limits. Click here for information about BigQuery quotas.
Using Google BigQuery Storage API
The Sisense Big Query connector allows you to use the BigQuery Storage API. The BigQuery Storage API provides fast access to data stored in BigQuery. The BigQuery Storage API is paid BigQuery service. For details about this service, click here.
Once the Storage API is enabled in BigQuery, it becomes available in Sisense and helps speed up the build times. On each import data request from Sisense, the executed query will be automatically optimized to work with the Storage API to import the data from BigQuery. In some use cases, using Storage API for large imports, you can achieve up to x5 faster build time.
When enabled, the driver checks the number of rows in an incoming result set table and the number of pages needed to retrieve all the results. If the number of rows and pages exceeds the threshold defined by Google Big Query, the driver switches to using the BigQuery Storage API. The Storage API feature allows for additional parallelism among multiple consumers for a set of results, thus enabling the driver to handle large result sets more efficiently.
Enabling Storage API in Google BigQuery
Enable the below service in the BigQuery API Library:
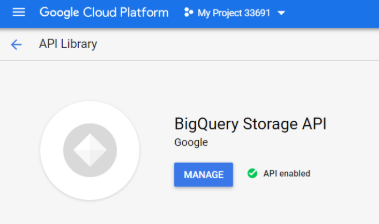
Storage API is a beta feature by BigQuery.
To learn more:
- For general information about the Storage API, click here.
- For Storage API pricing details, click here.
Troubleshooting
Out-of-Memory Issues
When building an ElastiCube with this connector, you might receive an "out of memory" error. To add more memory, see Troubleshooting Performance Issues.
Connecting Data to a Sisense Live Model
Sisense's Google BigQuery connector supports complex data types and partition types used in BigQuery. Complex data types, including Nested and Nested Repeated, are ingested automatically without any need to write SQL or functions.
Connecting to BigQuery
Sisense enables easy and quick access to databases, tables and views contained within Google BigQuery.
To connect to your Google BigQuery database, you need to provide a Project ID. The Project ID is a unique
identifier for your BigQuery project. You receive the Project ID when you create a project in Google BigQuery.
If you have already created a project and cannot find the Project ID, click here for help.
After you provide the Project ID, you can sign into your BigQuery account with your Google credentials. Once Google has authenticated your account, you can select what tables are to be imported into Sisense.
Note:
If you are connecting to a Google service remotely (for example, if you are on a Linux deployment), and the address of Sisense is something other than localhost, Google requires that you connect using the OAuth 2.0 protocol. See Google Authentication for more information.
To add a Google BigQuery live connection:
-
In the Data page, open a live model or click
 to create a new live model.
to create a new live model. -
In the Model Editor, click
. The Add Data dialog box is displayed. -
In the Add Data dialog box, click Google BigQuery.
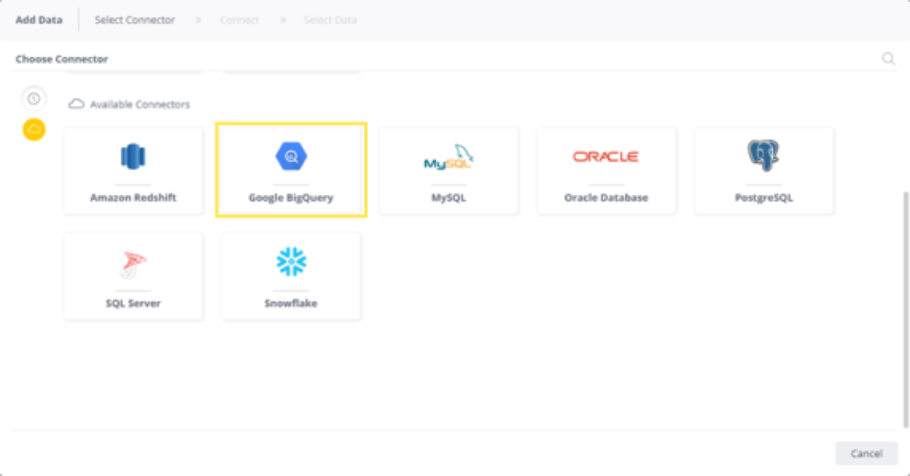
Note:
User parameters (which are defined in the User Parameters area of the Sisense Admin console) may be used for these BigQuery connection settings:
- Project ID
- Service Account
- Dynamic Schema
For more information about user parameters and the Dynamic Schema functionality, please refer to Managing Live Dynamic Connections.
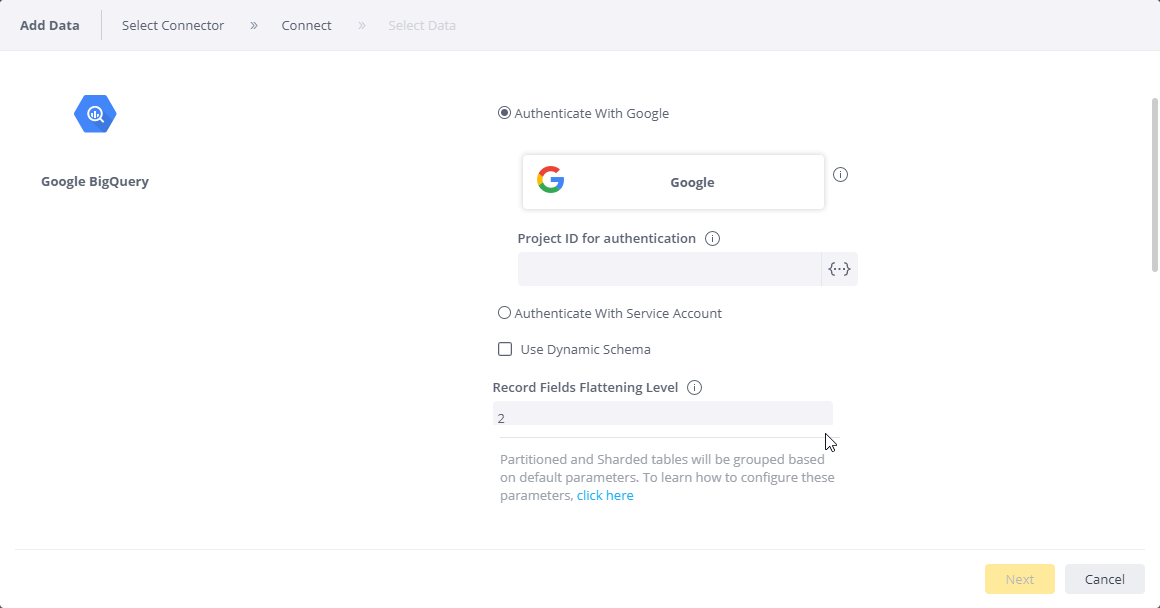
-
In Project ID, enter your BigQuery Project ID. This project ID is only used for authentication. Once you log in, you gain access to all the projects to which you have Google Big Query permissions.
If you have already created a project and cannot find the Project ID, click here for help.
-
Click Sign in with Google and enter your email, and then select Next to enter your password. If you have multiple accounts, select the account that has the Google BigQuery data you want to access and enter the password, if you are not already signed in. You must be signed out of all other Google accounts.
-
Click Accept to allow your Sisense Server to access your Google BigQuery data.
-
Close the browser window when notified to do so.
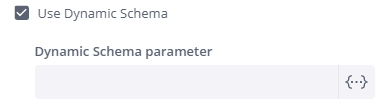
-
(Optional) Use the Dynamic Schema option to automatically select the schema defined for your user (or user's group) in the User Parameters area of the Sisense Admin console.
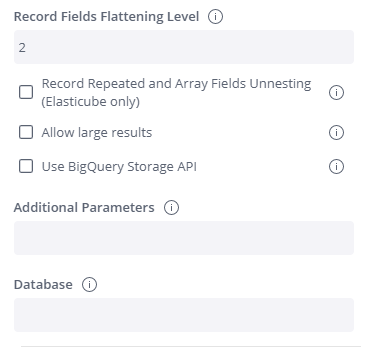
-
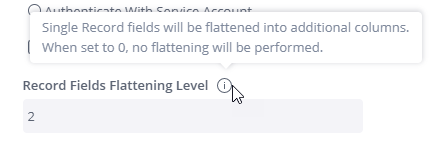
Record Fields Flattening Level - This option flattens Single Record fields into additional columns. Enter the number of nested levels you want to flatten. When set to '0', no flattening will be performed. For example, in a table with nested data depth of seven, you may choose to flatten only the first two levels. The data on the other levels will not be imported into Sisense.>
-
Record Repeated and Array Fields Unnesting (Elasticube only) - Ignore when configuring a Live connection.

-
Click Allow Large Results if your BigQuery table is larger than 128 MB. Important: This option is not usually recommended for Live connections because it is mainly for large import queries. However, for some use-cases with big data volumes, it could be relevant for Live models as well. When importing query results larger than 128 MB, BigQuery creates a temporary table (see above, or click here for more information). For this table to be created, you must be granted the Bigquery.tables.create permission in BigQuery (click here for more information). If you do not have this permission, the query results will not be imported into Sisense. The message that Sisense issues in this case is "Response too large to return. Consider setting allowLargeResults to true in your job configuration."

Notes about Temporary Tables
- The Sisense BigQuery connector creates temporary tables in BigQuery under a specified dataset. By default, temporary tables exist for 24 hours.
- From Sisense Version L8.2.6SP (Linux), newly created temporary tables will be written to a hidden dataset
named
_simba_jdbc(hidden datasets are not visible in the BigQuery Web UI). - You can customize the behavior of the "allow large results" feature.
- To change the location of the temporary tables, add the parameter
LargeResultDataset=<datasetName>to the Additional parameter field in the connection settings page. - To change the expiration date of the dataset, add the parameter
LargeResultsDatasetExpirationTime=<expirationTime>to the additional parameters field in the connection settings page.<expirationTime>is in milliseconds. This dataset must have an expiration date, otherwise the temporary tables will not be deleted.
- To change the location of the temporary tables, add the parameter
- You will need to manually delete temporary tables that were created prior to Sisense Version L8.2.6SP.
-
Use BigQuery Storage API - Select this option to use the BigQuery Storage API which provides fast access to BigQuery managed storage by using an RPC-based protocol.

-
Additional Parameters - Use this option to enter additional configuration options by appending key-value pairs to the connection string, (for example, timeout=10;).

-
Database - Enter a database name if you do not want to get a list of databases.
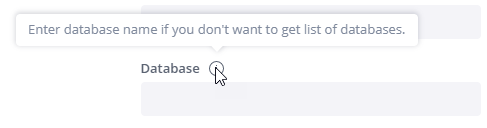
The default Database is an optional property in the connection to a data source. When specified, it acts as a starting point or shortcut, automatically selecting a database during the connection setup to streamline user workflows.
IMPORTANT:
The default Database is not a security feature. It does not restrict Sisense users from accessing other databases within the data source. Access should be regulated through user permissions in the Google BigQuery database management system.
-
Click Next. All tables and views associated with Google BigQuery are displayed.
-
From the Tables list, select the relevant table or view you want to work with. You can click

next to the relevant table or view to see a preview of the data inside it. -
After you have selected all the relevant tables, click Done. The tables are added to your schema.
Temporary Tables: Known Issues
In Sisense versions below 8.2.1 (Windows), temporary tables do not expire by default. To change this behavior:
-
Manually refresh the connection at the data source level by changing the connection in the Data tab. This applies an expiration date to temporary tables.
-
In BigQuery, in the dataset of the building table, set Default table expiration to Other value than "Never". All newly created tables of any given dataset will inherit the dataset's expiration period.
Rebuilding Parent Tables
Sisense provides a unique solution to rebuilding the parent table from its constituent sharded tables (grouped view).
For this, Sisense provides an external file, where you can indicate the custom prefixes or regular expressions (Regex) by which to group the shared tables into one parent table.
To group the shared tables into a single parent table:
-
Open the prefixes.json file (you can open it in Notepad). This file is located in the following directory:
...ProgramData\Sisense\DataConnectors\JVMContainer\Connectors\GoogleBigQuery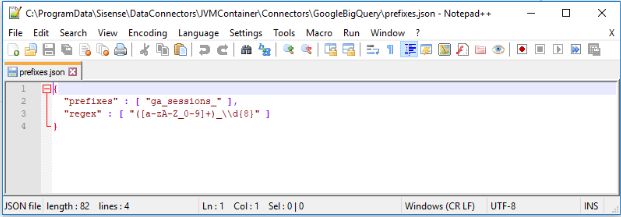
This file contains default prefix and Regex parameters that group all Google Analytics daily tables of the format "ga_sessions_YYYYMMDD" into one parent table.
-
To refine the grouping, modify the default parameters or add additional parameters as relevant to your data, and save the file. Make sure that the prefixes row is separated by a comma from the regex row.
-
To update your data model based on the new parameters, do one of the following:
-
From the Connection Wizard, jump to a previous step and return to the step you were on.
-
From the data model, open the Connector Wizard to add another table.
-
In both cases, The Connector Wizard will display the parent table, grouped from the sharded tables based on the indicated parameters.
Controlling the Partitions to Import with Custom Queries
Note:
This feature is available in Live data models starting from Sisense version 8.0.1. On earlier versions it is available only in ElastiCube data models.
Google BigQuery supports partitions and sharded tables to improve performance, availability, and maintainability.
The Sisense BigQuery connector provides the following abilities to run queries on BigQuery's table partitions and sharded tables:
-
Partitioned tables : Tables that are partitioned based on a TIMESTAMP or DATE column. The Sisense BigQuery connector enables querying the partitions via filters and custom queries, simply by the where clause sent to BigQuery.
-
Tables partitioned by ingestion time : Tables partitioned based on the data's ingestion (load) date or arrival date. The Sisense BigQuery connector enables using BigQuery SQL functions via custom queries to retrieve the requested partitions. Click here for details about these two methods.
-
As an alternative to partitioned tables, Google BigQuery enables sharding tables using a time-based naming approach, such as [PREFIX]_YYYYMMDD. This is referred to as date-sharded tables . See here for details. The Sisense BigQuery connector supports the ability to view the parent tables (grouped view, as Wildcard Select statement) while running queries per the partitions as filters.
You can import subsets of your partitioned and sharded tables into Sisense using SQL.
Note:
Starting from Sisense version 8.0.1, you can create custom SQL queries in Live data models. With Live table queries, you can now add and transform data and build custom business logic for analytics from Live models using custom SQL. Using this feature you can add a WHERE clause on your specific partition. For details, see Creating Custom Live Table Queries.
Querying Nested Objects
BigQuery supports nested records and arrays within tables. Nested records in BigQuery can be Single or Repeated records. These record types are imported into Sisense as:
-
Single records - as additional columns
-
Repeated records - as additional columns and rows
Example: A BigQuery schema that has Single and Repeated records:
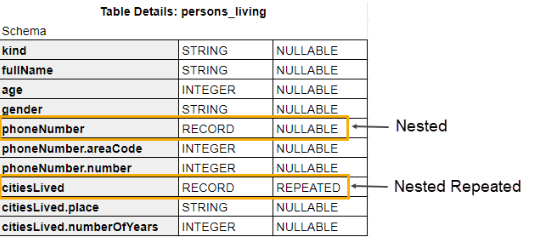
would be imported into Sisense as:

Click here for more information.
Sisense ingests both nested records and arrays automatically without any need to write SQL and functions:
-
Nested data type: Flattens records/arrays to columns with the ability to choose how many levels to expand.
-
Nested Repeated data type: Flattens repeated records to rows and columns automatically, using the UNNEST function.
Nested Objects
BigQuery supports Nested data as objects of Record data type.
When importing data into Sisense, you need to indicate how many levels of nested data you want to flatten (see Connecting to Google BigQuery). In Sisense, data on these levels will be flattened to columns using the dot operator (.).
Data on the nested levels that you chose not to flatten is not imported into Sisense.
Array Objects
BigQuery supports Nested Repeated data as arrays of Repeated Record data type.
When importing data into Sisense, Nested Repeated data type is flattened to rows and columns automatically using the UNNEST function.
Data in Array (primitive) data type is imported into Sisense. Sisense converts this data to un-indexed strings.
Enabling Storage API in Google BigQuery
Note:
For Live models, Sisense recommends disabling the Storage API in Google BigQuery. This feature works best when importing large data volumes into ElastiCubes.
Enable the below service in the BigQuery API Library:
Storage API is a beta feature by BigQuery.
To learn more:
- For general information about the Storage API, click here .
- For Storage API pricing details, click here.
Source Limitations
- The following functions are not supported for Google BigQuery: Cot, Diff, Mod, Round
- Maximum 15 nested levels (click here for details)
- Maximum query length: 1 MB
- Maximum response size: 128 MB compressed. This limitation can be overcome by clicking Allow Large Results Set as explained in Connecting to Google BigQuery .
- Query execution time limit: 6 hours
- Maximum number of tables referenced per query: 1,000
- Concurrent queries - based on the account rate limits. Click here for information about BigQuery quotas.
The Sisense Big Query connector allows you to use the BigQuery Storage API. The BigQuery Storage API provides fast access to data stored in BigQuery. The BigQuery Storage API is paid BigQuery service. For details about this service, click here.
Once the Storage API is enabled in BigQuery, it becomes available in Sisense and helps speed up the build times. On each import data request from Sisense, the executed query will be automatically optimized to work with the Storage API to import the data from BigQuery. In some use cases, using Storage API for large imports, you can achieve up to x5 faster build time.
When enabled, the driver checks the number of rows in an incoming result set table and the number of pages needed to retrieve all the results. If the number of rows and pages exceeds the threshold defined by Google Big Query, the driver switches to using the BigQuery Storage API. The Storage API feature allows for additional parallelism among multiple consumers for a set of results, thus enabling the driver to handle large result sets more efficiently.