Build to Destination Benefits and Considerations
Last updated: June 10, 2026
| Tier | Deployment |
|
|
The Build to Destination (B2D) functionality aligns with the customer need for agile and flexible data management. New requirements and constraints are arising on a frequent basis, and a single stack tool is required to support these needs. Examples include Governance restrictions, immediate scale needs, simple migration to Live Connection, PoC, Materialization, Self Service and more. All of this is achieved using the known Data Model Interface.
B2D exploits the known build capabilities and leverages them with additional features that are designed to work well with the designated CDWH provider, such as Build with Upsert, Extended JDBC data types support and the ability to choose the preferred SQL dialect in Custom Table/Column.
Note:
See Choosing the Right Data Model for detailed information about how to choose the best type of data model for your business requirements.
B2D Benefits
Update Insert (Upsert)
In addition to the current build type options available at the Table level (Full, Append, Accumulate, Changes Only), data modelers can choose to build with Update Insert (Upsert). This additional strategy aligns with the growing customer need to scale and better manage their data, while improving build times. See Select Build Behavior in Working with Build to Destination.
Improved Build Flow
Build Duration is optimized on each consequent build. This is achieved by prioritizing the process stages and optimizing the parallelism process.
Short Circuit Optimization
In the use case when the source and destination are on the same CDWH, the data is copied locally inside the CDWH and does not pass through the Sisense import process (parquet file, upload, bulk insert). This flow is designed in this manner to remove I/O and Network redundant steps, and hence to improve build performance.
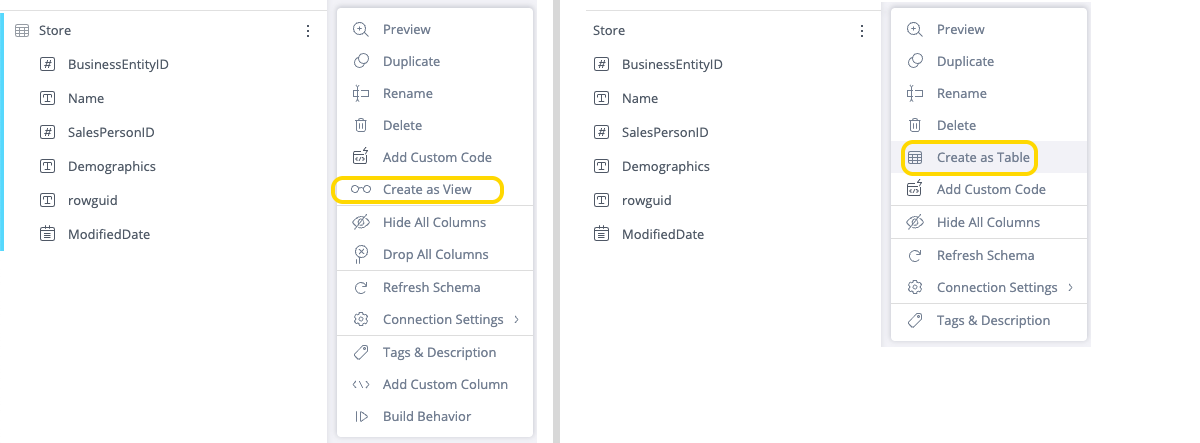
Create Table as View
When Data Modelers create B2D models, this feature enables them to create Views in the destination, without duplicating existing data in the CDWH, thereby better utilizing their flows. For example, a CSV file can be combined with an existing Snowflake table without adding duplicate tables in the CDWH. This is done by selecting Create as View from the table level. In order to use this feature, the source and destination must be the same. After a table is created as view-only, it can be changed to create a writeable copy of the table by selecting Create as Table. The default setting is "Create as Table". Tables utilize build and query performance but keep additional storage.
See Using the Model Editor for more information.
Supported Data Types in Model
B2D supports 17 JDBC data types in the Data Model. This applies to Source (Imported) Tables, Custom Columns and Custom Tables. A list can be found Introducing Live Models.
Custom Dialect
When data modelers generate a Custom Table or Custom Column, they have the option to choose between the database dialect and the Sisense dialect in B2D. When choosing the Sisense SQL dialect, the SQL is translated to the destination dialect. This allows more flexibility for customers who are used to the Sisense SQL dialect. Read Working with Build to Destinationfor how to works with Custom Columns and Tables.
Note:
Writing in the destination' dialect enables a wider set of SQL capabilities.Custom Tables and Custom Columns Process on CDWH
The Custom Columns and Custom Tables processing is done and applied in the CDWH. As with the ElastiCube build process, you first generate the required tables, and then generate the required columns and tables in the CDWH. This additional optimization feature allows faster build times by reducing I/O processing time and utilizing the CDWH strengths.
Different Connectivity Configurations for Query and ETL
There are two major benefits for using different connections:
- Security - Making sure the Query Model and the Processing Model use different connections ensures that viewers and dashboard designers are not able to use DML commands on the B2D Data Source.
- Cost Saving - CDWHs that support independent physical DWH storage and processing engine, enabling the use of the same DWH Storage with different processing engines. The ability to introduce a different processing engine utilizes customer costs.
Flexible Schema Selection
Data modelers can pick the designated schema as part of the destination in the B2D data model. This allows the data modeler to work with different schemas in different data models. The schema must be a new one, and not an existing one in the destination. Each cube must have a different schema.
Optimized BI Database
Utilizing the Build capabilities ensures there are no interruptions to queries during the build process. A different data set is generated, processed and replaced once completed.
Feature Onboarding and Backwards Compatibility Considerations
| Question | Answer |
|
Does the Build to Destination (B2D) feature need to be enabled? |
Yes, an Admin must enable "Build Destination" from the Admin tab in
Feature Management (i.e., search for and select "Feature
Management"), in the Management section.
|
|
Does enabling B2D require me to do anything immediately? For example, would any of the existing logic (e.g., cube building) be affected? |
No, the system will continue to work as-is. Onboarding Build to Destination (B2D) can be done at your own leisure and enabling the feature does not affect any of your existing capabilities. |
|
What are the current prerequisites for using B2D? |
You will need access to AWS S3 storage and a Snowflake or Redshift to act as the data warehouse. |
|
Once I enable it, what do I need to do? |
Basic instructions for getting started with B2D:
|
|
Can I switch an existing ElastiCube to build against a destination database? |
Yes, the switch is as simple as configuring the build to the given destination database. For example, switching from ElastiCube to Snowflake/Redshift. |
|
If I switched the ElastiCube to a build destination such as Snowflake/Redshift, can I switch it back to the ElastiCube build to MonetDB? |
Yes, the switch is as simple as selecting ElastiCube to be the destination database. |
|
Can a cube be built to more than one destination database at the same time? |
No, once the cube is switched to the given build destination it will only build there. |
|
Can I have different cubes running against different destination databases (side by side)? For example, cube 1 is building to MonetDB while cube 2 is building to Snowflake/Redshift. |
Yes, cubes can be selected to build against MonetDB while others could be against a database such as Snowflake/Redshift. For example, a cube cannot be built to MonetDB and Snowflake at the same time. If you wish to compare the built data (as a test for example), you will need a second duplicated cube for comparison purposes. |
|
How can I test my connection setup for the destination database? |
It cannot be tested initially and will be validated only upon running the build against the given configured destination database. You will only then be able to confirm the connection is correct and established. |
|
Can the B2D be configured via the regular Admin GUI? |
Configuration is performed via Sisense APIs. Refer to future release content to confirm if GUI oriented configuration becomes available. Other types of GUI configuration options via Admin that pertain to S3 or Snowflake/Redshift do not relate to the B2D feature. The existing connector configuration pertaining to the given destination database for Snowflake/Redshift is not used by the B2D feature to establish connection. The S3 bucket configuration is also not used for this feature. |