Analytical Engine
Last updated: June 11, 2026
| Tier | Deployment |
|
|
|
Background - Original Translator & Analytical Engine
Original Translator Overview
The Sisense translation engine is a core component within the Sisense analytics platform that facilitates seamless interaction between Sisense's internal query language and various destination databases. Its primary function is to convert Sisense's widget definitions into the specific SQL dialects required by different database systems, such as MonetDB, Snowflake, or Redshift. It interprets the data model and the widgets on dashboards, generating SQL statements optimized for the target data store.
The translation engine ensures that queries are executed efficiently and accurately on the target databases, optimizing data retrieval and manipulation processes.
While it is functional, the original Translator is generally considered less efficient compared to the newer Analytical Engine, which offers improved speed, stability, and functionality. The original Translator was designed with a "loose" data modeling approach, using simple table relationships and heuristics to determine join paths. While this method allowed flexibility, it sometimes led to inconsistencies in query results. To improve accuracy and control over query generation, Sisense introduced the Analytical Engine, which enforces a more structured approach using dimensional modeling principles.
Transition to the Analytical Engine
The Analytical Engine improves query precision by allowing you to define explicit modeling rules. This structured approach results in more controlled and optimized queries. However, because its methodology differs from the original translator, query results may not always be identical between the two. To mitigate potential issues, starting with version L2025.2, Sisense includes a fallback mode, "Compatibility mode", that reverts to the original translator, which you can set if you notice that the Analytical Engine encounters difficulties generating the expected results. This is a per model setting.
To set the translation mode ("Analytical engine" or "Compatibility mode"):
Only users with access to the Data tab, including Admins, Data Admins, and Data Designers, can set the translation mode.
-
Open the Data tab.
-
Select the relevant model.
-
Click
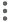 > Analytical Engine Settings.
> Analytical Engine Settings.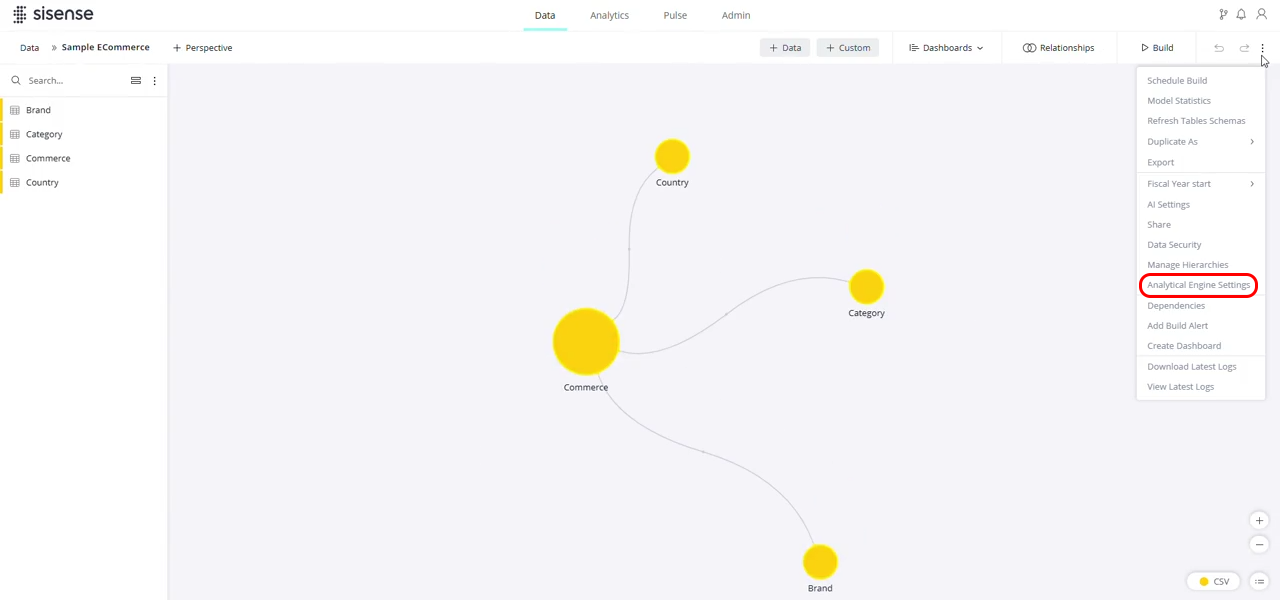
The Analytical Engine Settings window opens.
-
Select the desired translation mode:
-
Analytical engine - Default for new models.
-
Compatibility mode - Follows the system configuration and falls back to the original translator for unsupported queries. If you select this mode, you will be prompted to select a reason and optionally provide additional details. This data will help us:
-
Identify gaps in Analytical Engine functionality
-
Prioritize improvements for a seamless transition
Note:
When moving from Compatibility mode to the Analytical engine, there is a strengthening and improvement of formula validation. In the past, for certain formulas, some syntax errors were allowed to pass in order to provide more flexibility and a smoother workflow. In the new mode, however, the focus is on clarity and the elimination of ambiguity. As a result, formulas that are not defined in a clear and explicit way, meaning cases where the user’s original intent would have to be guessed, will now fail validation. This reflects our approach of not providing results that might be inaccurate or uncertain. While most formulas will continue to work in exactly the same way as they have before, some minor manual adjustments to existing formulas may be required to adapt to the new mode.
-
-
To apply the changes and ensure they take effect during query execution:
-
For EC and B2D models: Build the model or select Publish Semantics.
Note: Using Publish Semantics is recommended when only Analytical Engine settings have changed, as it avoids a full data rebuild. Modifications to Analytical Engine Settings are applied immediately. However, for EC and B2D models: if the model is currently undergoing an active build, the modifications will not be automatically applied. Once the build completes, you must select Publish Semantics to ensure the new settings take effect for subsequent query executions.
-
For Live providers: Publish the model.
Key Differences and Advantages
The Analytical Engine provides several improvements over the original Translator:
-
More precise query generation – By enforcing stricter model definitions, it produces more consistent and predictable results.
-
Performance optimizations – Generates more efficient SQL queries, reducing execution time.
-
Improved query readability – Users can better understand and control how queries are constructed.
-
Enhanced support for Live models and Build-to-Destination (B2D) – Provides more stability and flexibility when querying live data.
-
Minimized reliance on many-to-many relationships – Leads to more efficient and performant queries.
-
Support for SQL capabilities – Enables functionality such as left/outer joins and calculated dimensions, with future expansions planned.
Analytical Engine Overview
Sisense's modeling framework is a set of modeling languages and algorithms for BI analysis. Sisense's Analytical Engine is an algorithm that enables you to generate your query in the SQL dialect of the specific data-source with low-no code. The query is generated according to the widget elements (for example, measures and filters) and the user's data security role. It then executes the SQL query on the data source.
The Analytical Engine is based on the Dimensional Modeling methodology, which is a logical design technique that presents the data in a standard, intuitive framework that allows high query execution performance at scale.
Note:
The Analytical Engine only works in Linux environments.
In addition to supporting ElastiCube connectors, the Analytical Engine also supports live providers. For the list of live data sources supported by Analytical Engine see Live Data Source Connectors in Data Source Connectors.
The Analytical Engine:
- Enables customers to perform real-time analytics, directly over the data provider (Live).
- Leverages the provider's syntax via the open source Apache Calcite (https://calcite.apache.org/).
- Improves the performance and comprehensibility of the SQL queries.
- Defines the query in a very structured way, for improved readability and comprehensibility.
- Validates the query components on widget load and provides actionable error messages when necessary.
- Returns a null value if the query is invalid (due to filters or measures).
- Queries table values (not keys), for better null handling and advanced calculations.
- Exposes the generated SQL query to the dashboard designer, while respecting data security rules.
- Calculates top ranking filters per widget context, simplifying the implementation of the top ranking functionality for dashboard designers.
Analytical Engine's Extended Query Capabilities
Null Handling
By default, Null values are now displayed, and can be filtered out by the user. Null can also be used as a key. The Analytical Engine joins dimension tables when selecting entries, including the null results.
Top/Bottom Ranking Filter Handling
The Analytical Engine handles top/bottom ranking requests as follows:
- When each item has a unique rank, the results are ordered by the rank.
- When multiple items share a rank, those items are further sorted according to the other dimensions used for the presentation of the results (within the rank).
- When the Analytical Engine joins dimension tables when selecting entries, it includes the null results. This means that for top ranking filters, null can be a top ranking result.
Note:
-
For Live data models - Null values are presented when the top/bottom-ranking is applied.
-
For ElastiCubes - The default is that null values are not presented when the top/bottom-ranking is applied. The nulls can be presented if required, via a feature flag configuration; however, this is not recommended due to potential unintended side-effects. For assistance with this, contact Sisense support.
Filtering
The Analytical Engine inserts filtering clauses into the innermost SQL statement. This means that filtering is the first operation performed, minimizing the number of rows that need to be scanned in order to process the query. Complex filters, such as top ranking and filter on measure are significantly improved as a result.
Original Data Types
Casting
Casting is only applied when necessary, such as when calculating an average or handling division of integers, to maintain the original data type wherever possible. This improves performance and the accuracy of results.
Better Precision for Float Numbers
Float numbers inherit the original datatype from the live source, yielding more accurate results.
Query JOIN Path
Sisense Low-No Code approach for mashing up data and dashboard design can sometimes result in a query that is generated by the Analytical Engine that is not optimized to the specific analytical use case. A big impact on both query execution time and result correctness is the Join Path that is determined by the Analytical Engine, to calculate filters and measures that correspond with the widgets elements.
System
The Analytical Engine uses Dimensional Modeling concepts to generate queries, resulting in improved and consistent path selection - only schema changes affect the JOIN path in the generated query.
User Impact on the Query JOIN Path
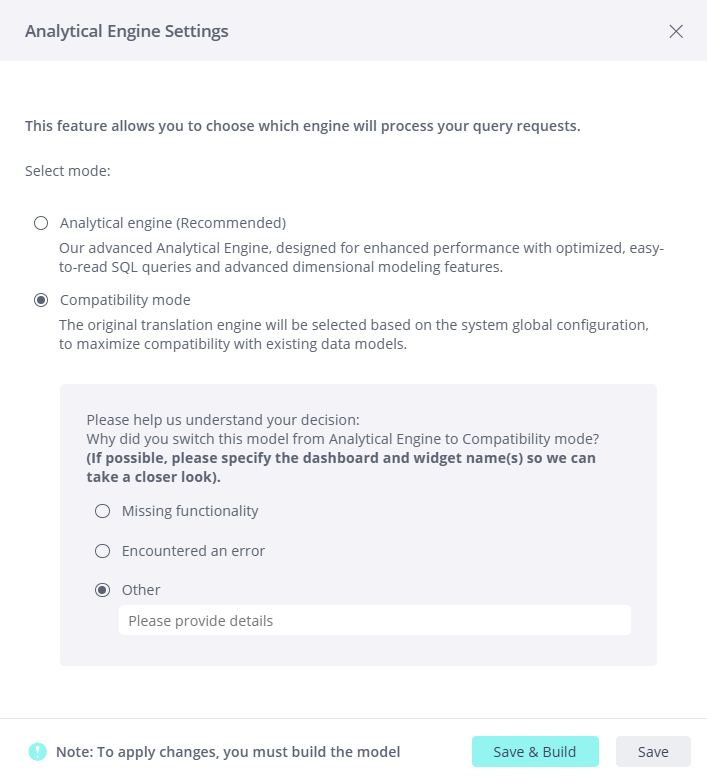
ForceScope Filter
By default, the Analytical Engine ignores "Include All" filters when selecting the join path. If a dashboard designer wants to control the join path and use the Include All functionality, the following must be added to the filter's Advanced tab (see Creating Dashboard Legacy Filters):
This enforces adding the table to the join path.
Performance Improvements of SQL Queries
The Analytical Engine improves the performance of SQL queries by:
- Calculating measures from the same table simultaneously in one scan.
- Performing caching per security role, and can be used by all users with the same data security role.
- Applying filters once for all widget measures.
Comprehensibility of SQL Queries
The Analytical Engine displays the generated SQL query to the dashboard designer in a more comprehensible way. It:
- Generates shorter queries.
- Applies data security rules to your queries so data that must not be displayed to users is obfuscated with asterisks (***).
- Uses WHERE IN statements for filters, improving the accuracy of query results.
- Returns more accurate and predictable results for past period functions, such as Past X, DiffPast X, Growth, Growth Rate, GrowthPast X.
This greatly simplifies query debugging, and ensures that it yields the desired result.
Note:
To explore the generated query, use the analyze SQL query feature. To visualize it, use the Query Plan Analyzer. The older Jaqline add-on visualizer is not supported by the Analytical Engine.
Many-to-Many Relationship Handling
The Analytical Engine uses WHERE IN statements to:
- Reduce many-to-many scenarios. It is used in filters, to select data from several tables with higher performance.
- Maintain the integrity of the original data set total, for pivot table subtotals and grand totals. This improves the performance and simplicity of the SQL query calculations.
Example:
Data tables:
| FILMS_Table | |
|---|---|
| FILM ID | DURATION |
| 1 | 100 |
| 2 | 200 |
| 3 | 300 |
| CATALOG_Table | |||
|---|---|---|---|
| CATEGORY ID | CATEGORY | FILM ID | GENRE |
| 1 | Classics | 1 | Comedy |
| 1 | Classics | 1 | Horror |
| 1 | Classics | 2 | Drama |
| 2 | Trending in Israel | 2 | Drama |
| 2 | Trending in Israel | 3 | Comedy |
| 2 | Trending in Israel | 3 | Drama |
filter GENRE = Drama
DURATION (measure) => FILMS_Table
GENRE (filter) => CATALOG_Table
Query 1: WHERE IN
| Count(FILM ID) | Sum(DURATION) | Median(DURATION) |
| 2 | 500 | 250 |
Query2: Join - Adding GENRE as Slicer
| GENRE | Count(Film ID) | Sum(DURATION) | Median(DURATION) |
| Drama | 2 | 700 | 200 |
SQL:
Median(DURATION) - Join
SELECT "dTable_aCATALOG_agenre"."value" AS "genre_res"
,"median__duration_res"
FROM (
SELECT "t2"."genre"
,MEDIAN("t2"."duration") AS "median__duration_res"
FROM (
SELECT "t1"."genre"
,"t"."duration"
FROM (
SELECT "aFILMS"."aid" AS "id"
,"aFILMS"."aduration" AS "duration"
FROM "aBLOCKFLIX"."aFILMS"
) AS "t"
INNER JOIN (
SELECT "aCATALOG"."afilmXwAaid" AS "film_id"
,"aCATALOG"."agenre" AS "genre"
FROM "aBLOCKFLIX"."aCATALOG"
WHERE "aCATALOG"."agenre" IN (
SELECT "dTable_aCATALOG_agenre"."key"
FROM "aBLOCKFLIX"."dTable_aCATALOG_agenre"
WHERE "dTable_aCATALOG_agenre"."value" IN ('drama')
)
) AS "t1" ON "t"."id" = "t1"."film_id"
) AS "t2"
GROUP BY "t2"."genre"
) AS "it"
INNER JOIN "aBLOCKFLIX"."dTable_aCATALOG_agenre" ON "it"."genre" = "dTable_aCATALOG_agenre"."key"
ORDER BY "dTable_aCATALOG_agenre"."value"Median(DURATION) - Where In
SELECT MEDIAN("t4"."duration") AS "median__duration_res"
FROM (
SELECT "aFILMS"."aduration" AS "duration"
FROM "aBLOCKFLIX"."aFILMS"
WHERE "aFILMS"."aid" IN (
SELECT "film_id"
FROM (
SELECT "aCATALOG"."afilmXwAaid" AS "film_id"
,"aCATALOG"."agenre" AS "genre"
FROM "aBLOCKFLIX"."aCATALOG"
) AS "t"
WHERE "t"."genre" IN (
SELECT "dTable_aCATALOG_agenre"."key"
FROM "aBLOCKFLIX"."dTable_aCATALOG_agenre"
WHERE "dTable_aCATALOG_agenre"."value" IN ('drama')
)
)
) AS "t4"</pre>Example:
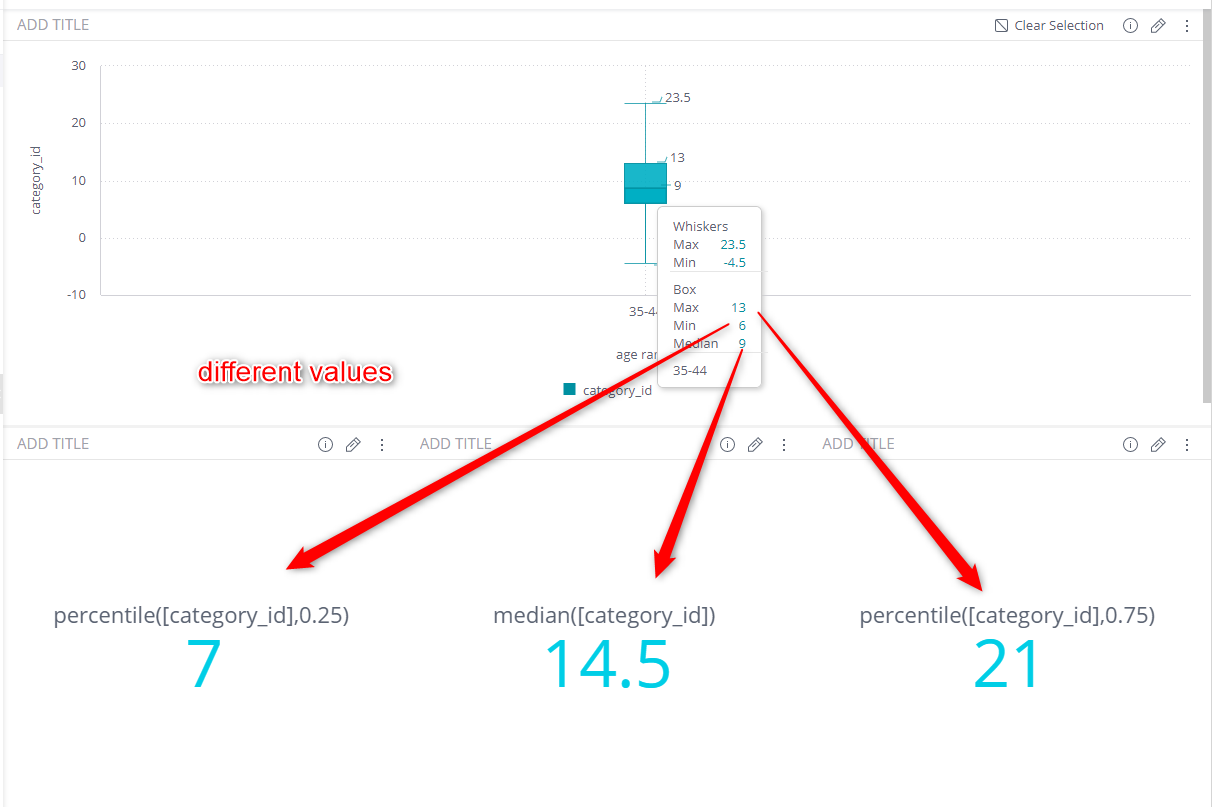
In the example below, age_range (from the Ecommerce table) is presented in the box plot and is considered as slicer for the calculation over category_id (from the Category table). The box plot calculation uses a JOIN statement, while the indicators use the WHERE IN statement. Hence, the results are different, but both answers are correct, as they are actually different business questions.
From Ecommerce:
filter: age range = 35-44
Boxplot - analyze category_id by age range
Indicators - analyze category_id
Data Source Function Requirements
The Analytical Engine commonly uses the following analytical functionality. This functionality is translated into the listed dependent SQL elements when sent to the data source, so the data source can run the query and retrieve the required result set. If your data source does not support these SQL elements, you will get an error if the SQL element is used. Therefore, it is important that you check whether your data source supports these SQL elements.
Note:
The SingleStore (MemSQL) connector is currently partially supported by the AE, but the AE is not enabled for it by default.
| Analytical Functionality | Description | Dependent SQL Element |
|---|---|---|
|
Using columns from two tables in a single widget |
For any reason such as calculation, filter, presentation |
JOIN Statement |
|
Using custom import tables |
Define the data model by an SQL statement |
WITH statement (CTE to return a temp table) |
| SUM | The total sum of a numeric column | SUM |
| AVG | The average value of a numeric column | AVG |
| MIN | The minimum value of a numeric column | MIN |
| MAX | The maximum value of a numeric column | MAX |
| Count | The number of members in a column without null values | COUNT |
| Duplicate Count | The number of distinct members in a column without null values | COUNT + DISTINCT |
| Query Limit | Limiting the number of rows returned in a result set | LIMIT + OFFSET |
| Presenting dates in widget |
Presenting data according to some date granularity |
DATE_TRUNC |
|
PastX Functions(for ex. pastYear) |
Calculating the same measure during a parallel time period versus the currently presented time period |
DATE_ADD |
|
Date Diff Functions(for ex. Day Difference) |
Calculating the difference between end and start times |
DATEDIFF |
|
RANK(1234,1224,1223) |
Calculating the rank of a value among the list of values |
ROWNUMBER / ROW & OVER + Partition By (Window Function) |
|
Running Sum/Average |
Calculating the running total of the measure by the defined dimension, according to the current sorting order in the widget |
OVER + Partition By (Window Function) |
|
MEDIAN |
The median value of a numeric column |
MEDIAN |
|
Percentile |
The percentile value of a numeric column |
PERCENTILE/N_TILE |
|
STDEV |
The standard deviation of the given values (Sample) |
STDDEV_SAMP |
|
STDEVP |
The standard deviation of the given values (Population) |
STDDEV_POP |
|
VAR |
The variance of the given values (Sample) |
VAR_SAMP |
|
VARP |
The variance of the given values (Population) |
VAR_POP |
|
LN |
The base-e logarithm of the given value |
LN / LOG |
|
LOG10 |
The base-10 logarithm of the given value |
LOG10 / LOG |
Known Issues / Limitations
-
Measured Value over Window function is not currently supported by the Analytical Engine on ElastiCubes.
-
MySQL does not support the Percentile, Median, and Quartile functions.
-
Analytical Engine does not currently support Highlight dashboard filters on text columns. Use standard Slice/Filter instead.