Many-to-Many Relationships
Note:
The image on this page were taken in the desktop version of Sisense , however, the same principles described on this page also apply to Sisense Online.
In databases, there are different types of relationships between tables and fields within those tables:
- One-to-One Relationship: In this scenario both sides of the relationship have unique values for every row.
- One-to-Many Relationship: In this scenario one side of the relationship will contain unique values for every row, but the other side of the relationship will contain duplicate values for any or all of the corresponding values in the first table.
- Many-to-Many Relationship: In this scenario, both sides of the relationship will hold duplicated values, causing excessive calculations for every query run against it.
The problem with many-to-many relationships is that it can cause duplications in the returned datasets, which can result in incorrect results and might consume excessive computing resources. This section provides solutions and workarounds to common scenarios with many-to-many relationships.
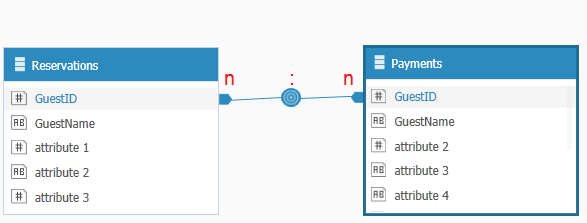
Example: A hotel may have a table with reservation data and a table with payment data. Both tables include the name of the guest. A guest can have multiple reservations under their name as well as multiple payments recorded on their name. If a relationship exists between the reservation and payment tables based on the guest’s name, a many-to-many relationship is created, as the guest’s name appears multiple times in each table.
There are several methods to resolve and bypass a many-to-many relationship. The solution depends on the business model and the logic of the business questions at hand. The following solutions differ by business logic and the schema at hand; each solution can be applied to each schema respectively.
The following sections cover:
- Testing your schema to see if it includes many-to-many relationships
- Understanding which scenario best fits your current schema
- According to your schema logic, applying the respective solution
Testing if a Relationship is Many-to-Many
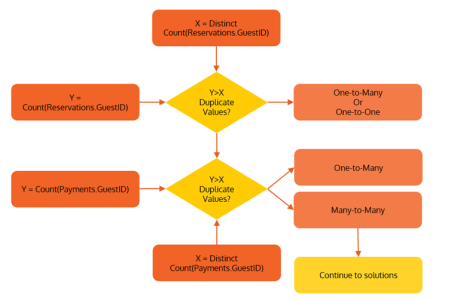
To check if a relationship is many-to-many, you need to check the cardinality of the relationship, and determine the number of unique and duplicate values on each side of the relationship.
When testing, if you get the same value for both the unique and duplicate values, then there is no duplication, and this will either be a One-to-Many or a One-to-One relationship. If the number of duplicate values is larger than the number of unique values, then this side of the relationship has duplicated values, and you will need to investigate the other side of the relationship. If the other side of the relationship yields unique values, this is a one-to-many relationship. If not, you have a many-to-many relationship.
Use the following SQL statement to test for potential M2M relationships:
-
In Sisense , open the relevant ecube file.
-
Click Add Data > Custom SQL Expression.
-
Enter and adjust the SQL statement below.
SELECT [Do I have duplications?]FROM (SELECT distinct_count(t1.col1)<>count(t1.col1) AS [Do I have duplications?]FROM [Table1] t1UNION allSELECT distinct_count(t2.col2)<>count(t2.col2)FROM [Table2] t2) AS tempGROUP BY [Do I have duplications?]
-
In the top right of the expression editor window, click Parse SQL Expression. If the expression parses successfully, click Preview result table.
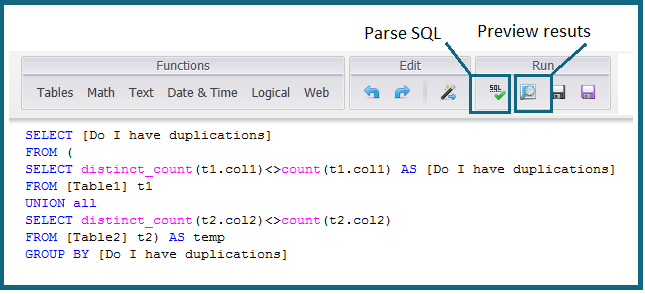
-
If the returned result is ‘True’ in both lines, a many-to-many relationship exists, and will need to be considered in the ElastiCube design.
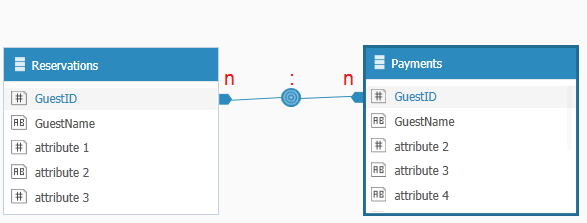
Many-to-Many Relationship Prior to Resolution
If the two values are equal, all guest IDs appear only once, making all values unique. Even if the other side of the relationship has duplicate values for guest ID, this is still a One-To-Many relationship, where the unique values are on the reservations side, and the duplicate values are on the Payments side.
If there are more than two tables connected to this relationship, that is, if there are more than two tables merged on the same field, a few more options exist. The solution for the single many-to-many relationship will be a sub-problem of this scenario. In this case, you’ll need to run the test on every table to see the uniqueness or duplication of the merged fields.
Two Tables with One Relationship
This section describes two possible workarounds when you have a schema that includes two tables with one relationship:
- Two Separate One-to-Many Relationships
- Creating an Aggregated Table
Two Separate One-to-Many Relationships
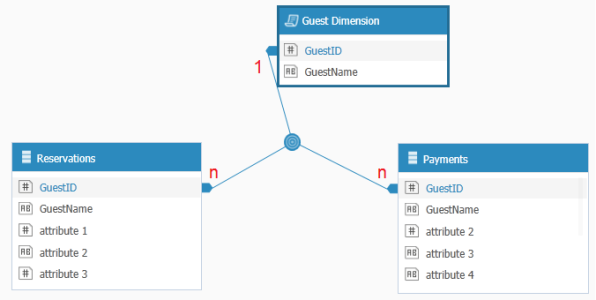
The direct solution for such a problem is to break this relationship into two separate one-to-many relationships.
The following diagram explains the testing logic:
-
Create a custom SQL expression in the Elasticube. In the expression of this table select all the individual values for the identifier column from both sides. The expression should look like this:
SELECT * FROM(SELECT DISTINCT r.GuestID, r.GuestNameFROM [Reservations] rUNIONSELECT DISTINCT p.GuestID, p.GuestNameFROM [Payments] p) AS G
This query will take all Guest ID values from both tables, and using the UNION statement, will bring in only the unique values from both tables, making this a complete list of all distinct Guest ID values. -
Merge the Guest ID field from the new ‘linking’ table to the other two Guest ID fields from the other two tables, thus creating two One-To-Many relationships.
You can now use this Guest ID field as the rows or axes elements of a widget, pulling in the unique values from the new Guest Dimension, with measures from the two other tables. See image above.
Creating an Aggregated Table
In situations where you have more than one fact table (a Fact table is a primary table containing the measures or fields used for calculations in the dashboard) in the ElastiCube , there are several situations when an aggregated table can resolve a many-to-many relationship.
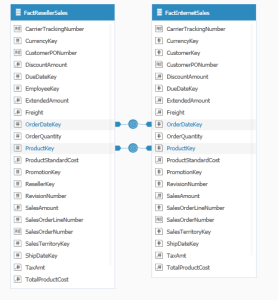
Two fact tables
Assuming you want to segment your data according to a few different dimensions, creating relationships directly between these fields can and will create many-to-many relationships in one of two ways, according to the schema:
- Both tables don’t hold unique values, and all values from one table are held in the second table. In this scenario either a linked dimension (as described in the first solution – Two Separate One-to-Many Relationships) or an aggregated table can be created which will hold all the unique values and the desired calculations for one of the tables. To create an aggregate table, create a custom SQL expression and aggregate values from the table that includes all values; its own, and the subset present in the other table with the following expression:
SELECT i.OrderDateKey, i.ProductKey, sum(i.DiscountAmount), sum(i.SalesAmount),
avg(i.UnitPriceDiscountPct)
FROM [FactInternetSales] i
GROUP BY i.OrderDateKey, i.ProductKey

This custom SQL expression will select the distinct OrderDateKeys and their corresponding ProductKeys from the FactInternetSales, grouped by these fields, together with single value aggregations for the different fields, in this case, Discount Amount, Sales Amount and the average unit Price discount. After merging the OrderDateKey and Product Key to the two other tables, you will be able to pull the values from this new table into the rows or axes panel of a widget in the Sisense Web Application with measures and additional aggregations from the two other tables.
Note:
The non-aggregated table needs to be a subset in terms of the primary fields from the aggregated table.
- Both tables don’t include unique values, and there are different values for several fields in both the tables. Resolving this scenario incorporates both solutions mentioned above. In this scenario, create an aggregated table and a dimension table (both described above). The final resolution should look like this:

Two Fact tables with a date dimension table and an aggregative Products table More than Two Tables with More than One Relationship
This section provides two possible workarounds when you have a schema that includes more than two tables with more than one relationship:
Options include:
- Using the Lookup function
- Concatenating two tables into one
Using the Lookup Function
In most scenarios, you will aggregate values according to a given ID from the unique side of the relationship to the duplicate side. However in specific cases it’ll be vice versa.
For example in the following scenario, in which we have three tables, and between them two one-to-many relationships, this can potentially create a many-to-many relationship, if you query the two leaf tables. This means that the query result table will have multiple rows which won’t be distinguishable one from the other.

Two consecutive Many-to-Many relationships Using the Lookup Function, you can import values from a remote table by matching values in a different column. This will create a new column in the table where you want to perform an aggregation of a given field(s), with the matching value of the identifying field from the other table. Taking the example of tables T1, T2 and T3, we’d like to run a query that will display aggregations from the duplicate IDs from T1, with a measure from T3. If you run the query as-is, you will get multiple values for the query’s result set, and we will not be able to run this aggregation. To resolve this, use the Lookup function to import the values from T3 into T2 and then re-run the query only on tables T1 and T2. Using the Lookup function, available in the ‘Miscellaneous Functions’ in the custom SQL editor, you can import the values of ‘M3’ from the ‘T3’ table into the ‘T2’ table. Create a new custom column, and use the Lookup function to import the values of attribute, In this case, the Lookup function should look like this:
Lookup([T3],[T3].[M3], [T2].id2,[T3].id2)
Running this statement in table T2 will import the matching values of M3 from T3 according to the matching results in ID2 between the two tables.
LOOKUP(remote_table,remote_result_column,current_match_column, remote_match_column)
Matches the current value with another value from a remote table. The result will be the value in remote_result_column for which the corresponding remote_match_column equals the current_match_column.

Two consecutive Many-to-One relationships after Lookup fix
Concatenating Two Tables into One
Assuming you have two separate tables with duplicate ID values in each, and each including different columns for each ID, you can create a new table including all values for every ID, and pull the aggregations from this new table.
Note that the two original tables; Table_1, Table_2 have different columns.
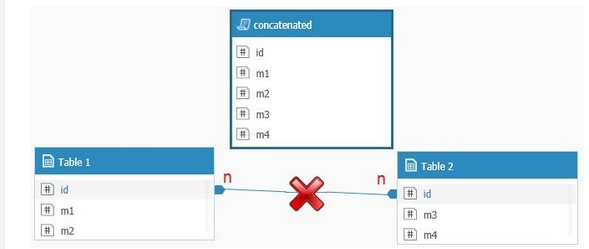
Concatenating tables
Using the following SQL statement, you can import the data from both tables, with the IDs and the columns respectively:
SELECT s.id AS id, s.m1, s.m2, ToInt( NULL ) m3 , ToInt( NULL ) m4
FROM [Table 1] s
UNION
SELECT t.id, ToInt( NULL ) , ToInt( NULL ) , t.m3, t.m4
FROM [Table 2] t
This will create a table with five columns:
Id
M1 (from table_1)
M2 (from table_1)
M3 (from table_2)
M4 (from table_2)
The values missing from each table respectively will be NULLs, which will result in the following table:
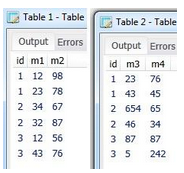
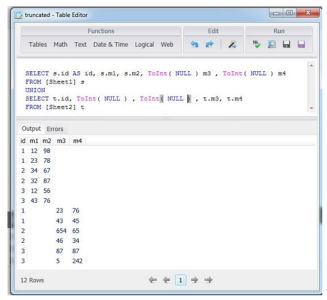
Concatenated table – result set
.r.