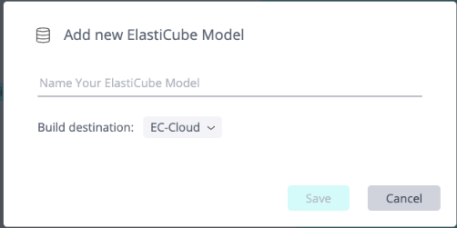
Setting Up a Cube to Build to the ElastiCube (EC) Cloud
| Question
|
Answer
|
|
How do I configure the cube to be built to the EC Cloud? |
When adding a new ElastiCube model, ensure that EC-Cloud is selected as the destination (it should be selected by default).
Sisense performs the rest of the configuration for you. |
|
Can I specify different databases for different cubes? |
Yes, as long as you specify them in the cube setup. If not specified, it will use the default. |
|
Are you required to set the schema name in the cube EC Cloud configuration? |
This is optional. Sisense will create a schema for you. If you choose to configure it, the cube build will create the given schema name which you configured. If you do not, an automatic name will be created which will consist of the given cube name and the Sisense Deployment ID for the instances running the build. If you configure the name of the schema, it is required to be unique to avoid conflicts from different build processes. In addition, if you enter characters that are not supported by the destination database, Sisense will change these characters to characters that are supported. |
|
What happens if the schema already exists? |
If the schema already exists in the database if the cube was never built, the build will fail and will NOT drop the existing schema. This is to ensure that no existing schema that has not been created by a cube build will be accidentally dropped. |
|
Is there a risk in the process of building a cube with a schema name that already exists in the destination database that contains the base originating data? Can the process by mistake drop an existing schema? |
No, the build process drops only a schema that was created by the building of the cube. Any existing schema cannot be dropped. |
|
Will switching an existing cube to use the EC Cloud feature retain all of the cube settings? For example, if Incremental was set, will the setting be applied after the first build? |
Yes, all cube settings are retained and not affected by the switchover. However, the first build for the given cube will be forced into running a full build upon the switch over to EC Cloud. Note that this is only relevant for existing cubes, and not for new cubes. |
|
What if for some reason I am using a generic JDBC connector to connect to EC Cloud? |
There is no way to use a Java generic connector setup for EC Cloud, as it uses only the built-in Sisense EC Cloud connector. If a generic connector is set up and used in the build for accessing the EC Cloud, it will be used for sourcing the data from these given databases only. |