Configuring B2D in Sisense
Last updated: June 10, 2026
| Tier | Deployment |
|
|
Overview
This topic includes:
-
Configuring the B2D Destination Storage - Using the REST APIs to set up an AWS bucket
-
Configuring the B2D Connection - Using the APIs and yaml files to create writer and viewer connections to the CDWH
Enabling B2D in Sisense
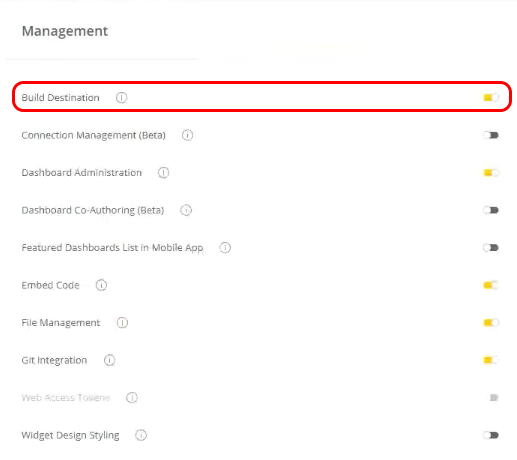
To enable B2D in Sisense:
-
Open the Admin tab and click the Feature Management link.
-
Under the Management section, toggle the Build Destination switch on.
Configuring the B2D Destination Storage
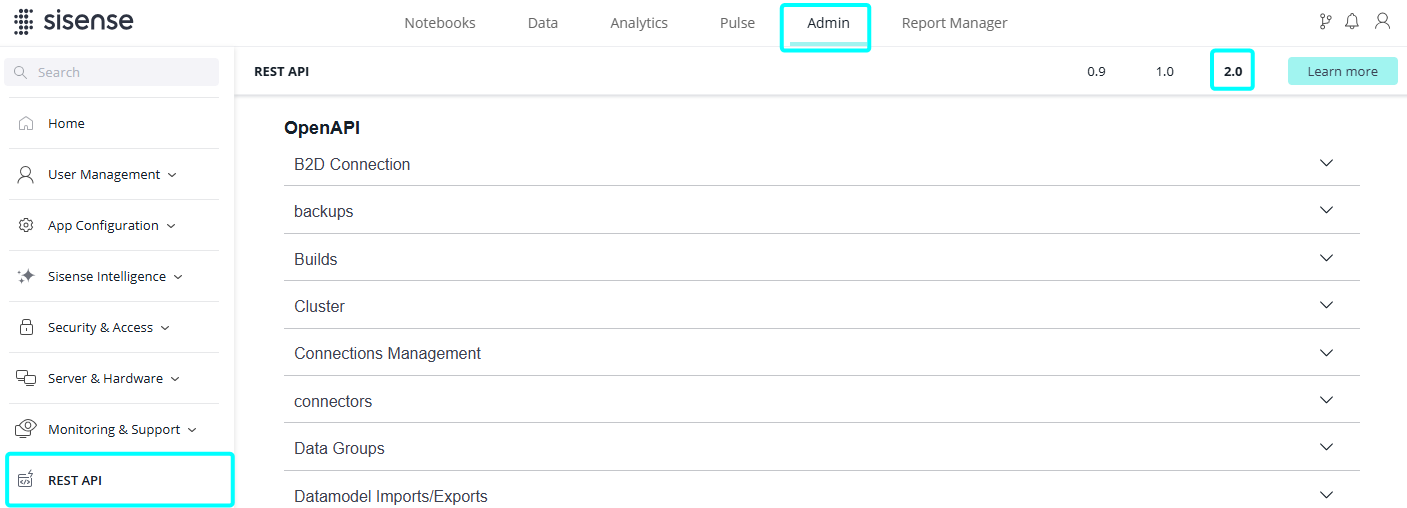
The Destination Storage REST APIs are used to configure an AWS bucket. This is where the B2D build process will copy the exported CSV (or Parquet) files during the build.
Note:
Snowflake and Redshift database destinations are built through Amazon S3.
In the Sisense application, click the Admin tab > REST API > 2.0 > and see the Destination Storage section to view all of the APIs:
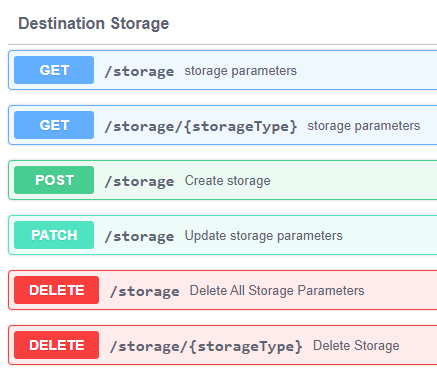
Parameters of the JSON:
-
name (string)
-
iamRole (string) - The role that was configured for the given bucket.
For example:arn:aws:iam::<?>:role/<name of role> -
storageType (string) - The type of storage used.
AMAZON_S3only. -
bucketName (string) - The name of the bucket that should be used. The bucket name must adhere to AWS policy (for example, it should be lowercase characters only).
-
bucketRegion (string) - The region where the S3 instance is located.
For example:us-east-2 -
secretKey (string) - The shared secret (text) for the key to access S3.
-
accessKey (text) - The key used to access S3
-
storageIntegration (string) - Optional when Snowflake is the destination. This can be used instead of access key and secret key.
Example:
{
"name": "test",
"iamRole": "arn:aws:iam::Add here your role number:role/Add here your role name",
"storageType": "AMAZON_S3",
"bucketName": "uploaddataredshift",
"bucketRegion": "us-east-2",
"secretKey": "Add here your secret key",
"accessKey": "Add here your access key",
"storageIntegration": ""
}
Configuring the B2D Connection
-
Click the Admin tab > Rest API > 2.0.
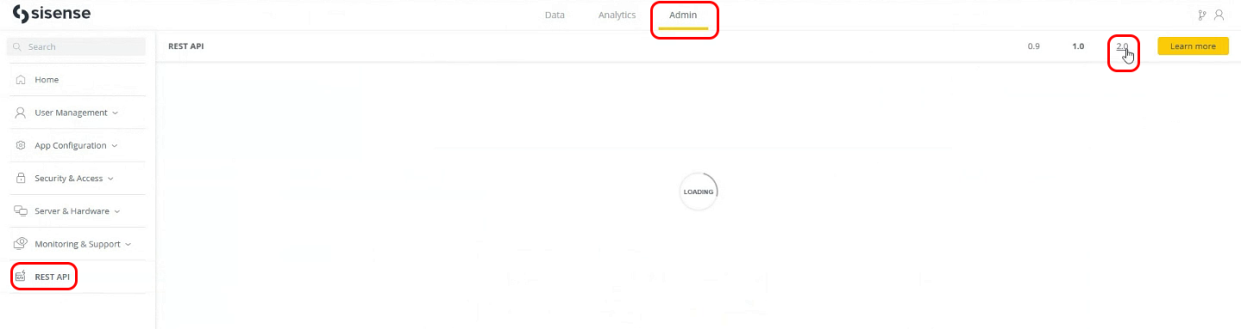
-
Under Open API, click B2D Connection.
-
Select the POST /b2d-connection endpoint.
-
Click Try it out.
-
Create the connections for a Viewer and for a Writer:
-
Enter the payload in the Request body:
-
Snowflake
-
ViewerCopy
{
"name": "Snowflake B2D Viewer",
"buildDestination": "snowflake",
"provider": "SnowflakeJDBC",
"parameters": {
"role": "VIEWER",
"Database": "SALES_DATA",
"privateKey": "/opt/sisense/storage/data/key.p8",
"account": "<account_identifier>",
"passphrase": "yourPassphrase",
"useKeyPairAuth": true,
"connectionString": "jdbc:snowflake://<account_identifier>.snowflakecomputing.com/?warehouse=<warehouse>",
"useModernRSA": true,
"userName": "sisense_b2d_viewer_user"
},
"description": "Connection with viewer permissions for accessing Snowflake Data Warehouse via Build to Destination (B2D)",
"permissions": "viewer"
} -
WriterCopy
{
"name": "Snowflake B2D Writer",
"buildDestination": "snowflake",
"provider": "SnowflakeJDBC",
"parameters": {
"role": "WRITER",
"Database": "SALES_DATA",
"privateKey": "/opt/sisense/storage/data/key.p8",
"account": "<account_identifier>",
"passphrase": "yourPassphrase",
"useKeyPairAuth": true,
"connectionString": "jdbc:snowflake://<account_identifier>.snowflakecomputing.com/?warehouse=<warehouse>",
"useModernRSA": true,
"userName": "sisense_b2d_writer_user"
},
"description": "Connection with writer permissions for accessing Snowflake Data Warehouse via Build to Destination (B2D)",
"permissions": "writer"
}
-
-
Redshift
-
ViewerCopy
{
"buildDestination": "redshift",
"createdByUser": "true",
"description": "string",
"enabled": "true",
"name": "redshift_viewer",
"ownerId": "string",
"parameters": {
"connectionString": "<place your connection string here>:5439",
"Database": "be",
"UserName": "<place your Redshift user name here>",
"Password": "<place your Redshift user password here>",
"Parameter": "allowMultiQueries=true",
"role": "VIEWER"
},
"permissions": "viewer",
"provider": "RedShift",
"supportedModelTypes": [
"EXTRACT"
]
} -
WriterCopy
{
"buildDestination": "redshift",
"createdByUser": "true",
"description": "string",
"enabled": "true",
"name": "redshift_writer",
"ownerId": "string",
"parameters": {
"connectionString": "<place your connection string here>:5439",
"Database": "be",
"parameter": "allowMultiQueries=true",
"role": "WRITER",
"UserName": "<place your Redshift user here>",
"Password": "<place your Redshift user password here>"
},
"permissions": "writer",
"provider": "RedShift",
"supportedModelTypes": [
"EXTRACT"
]
}
-
-
-
Click Execute.
Note:
-
Create the connections one at a time. That is, first create a connection for a Viewer according to the Viewer payload above. Then, only after creating that connection (after clicking Execute), create a connection for a Writer according to the Writer payload above.
-
If the Viewer and the Writer will be different users, the user name and password must be changed accordingly.
-
Using B2D API endpoints is the only way to create or manage B2D connections, as they are isolated from Connection Management (CM) and will return an error if a B2D connection is passed in a CM API payload. They also will not be displayed in the CM lists.
-
Configuring the Destination Database
The following are the instructions to configure Sisense to connect to and use the given B2D:
- Only one destination database can be set up at this point for each given provider (e.g., one for Snowflake and one for Redshift).
- Each destination database consists of a pair of configuration settings: One which defines the user used for the build with read/write permissions, and one for the query with read permission only.
| Parameter | Description | Values |
| connectionString | Connection string to the destination database. For Snowflake it includes the warehouse and user role. | For Snowflake:
jdbc:<snowflake >://<target address for the destination database> /?warehouse=<Name of Warehouse>&role=<WRITER or VIEWER> For Redshift: <target address for the destination database>:<database port> |
|
user |
The database user that will be used for the purpose of B2D. There should be one user with the write permission and another with the viewer permission. |
The name of the user. |
|
password (Redshift only) |
The password for the user. |
The user password. |
|
role |
The role of the user. |
VIEWER or WRITER. |
|
database |
The default database name. This value is used in the case no specific database is specified in the configuration of the B2D for the given cube in the UI. |
A database name that has been created already in the destination database warehouse being configured. |
|
permissions |
This setting will be used to determine which user to use for which operation, 'viewer' for query and 'writer' for build. |
'viewer' or 'writer'. |
|
buildDestination |
The build destination provider being used. |
Currently only 'snowflake' or 'redshift'. |
Build Configurations
Below are the B2D specific configurations that are used in the build process. The default settings are configured optimally and should not be changed. If you require changes, contact Sisense support.
|
Config Section |
Config Name |
Parameter |
Value |
|
Build |
useBuildOptimization.value |
This turns on or off the circuit breaker/build optimization. When enabled, it allows for a more efficient build when the source and destination are on the same database (e.g., if the data is sourced from Snowflake and the cube is built in that same Snowflake instance). |
On/Off |
|
Build |
dataFileSizeLimit.value |
Sets the size limit on the data file being created. Once the data size (in MB) is reached, the file will be closed, and a new file will be created. |
MB size number |
|
Build |
uploderFilesExtension.value |
The file format that is used to create the data file that gets uploaded to storage. |
Parquet or CSV (Based on the release, it might be done only for Snowflake) |
|
Build |
useDimensionTables.value |
When enabled, it creates dimension tables. (Based on the release, it might be done only for Snowflake.) |
On/Off |
|
Build |
enableBucketCreation.value |
If On, it auto-creates the bucket within the configured S3 based on the configured bucket name. If Off and no bucket exists, the build will fail. |
Text |
|
Build |
deploymentId.value |
The string of characters that are used in naming the schema when it is named automatically by Sisense (i.e., not configured by the user). |
Text |
|
Build-Connector |
CsvCompressionCodec.value |
The compression applied on data files: e.g., CSV uses Gzip. |
Compression method |
|
Build-Connector |
ParquetCompressionCodec.value |
The compression applied on data files: e.g., Parquet could be Snappy. |
Compression method |
|
Build-Connector |
destinationUploadThreads.value |
Number of threads that can run in parallel that can upload the data files to S3. |
Number of threads |
|
Build-Connector |
DestinationConversionsCircuitBreaker |
Stops serializing (converting) data of columns that fail to do so too many times. |
On or Off |
FAQ
| Question | Answer |
|
How do I configure a storage / bucket in Sisense? |
Follow the instructions above. |
|
Does the yaml file used for creating the configuration have to be placed somewhere specifically? |
No, but you must place it in a folder in which Sisense has permission to. |
|
Can I configure more than one S3 bucket at a time? |
No, only one bucket is configured overall for the given Sisense platform. You can change the bucket setup; however, you cannot add more than one. This attempt will fail at the command level. Therefore, once a bucket is configured, use an update to change the configuration (or delete/create). |
|
Are there any naming conversion restrictions on the bucket name? |
Note that the bucket name naming conversion must adhere to S3 policy (for example, it could have only lower-case characters in the name). |
|
Are there any recommendations on the AWS region to use for the storage? |
To improve performance, it is recommended that the region for the storage will be the same as Snowflake/Redshift. |
|
Can you have more than one Snowflake/Redshift setup for B2D? |
No, for each given B2D there should be only one pair of settings (one for the viewer and one for the writer). Note that this might not be blocked by the command, and therefore if a second set is inserted by mistake it should be removed. |
|
What is the purpose of defining a database in the setup? |
The database name parameter in the setup is used as the default value. Meaning, if no database is entered in the cube B2D settings, this value will be used. |
Yaml File Examples
The following are examples of configured connections in a yaml file.
connections:
- connectionString: jdbc:snowflake://sisense.aws.com/?warehouse=EXWH&role=WRITER user: WRITER password: expassword role: WRITER database: EXDB permissions: writer buildDestination: snowflake - connectionString: jdbc:snowflake://sisense.aws.com/?warehouse=EXWH&role=VIEWER user: VIEWER password: expassword role: WRITER database: EXDB permissions: viewer buildDestination: snowflake - connectionString: sisense.redshift.com user: exadmin password: expassword database: exdb permissions: writer buildDestination: redshift - connectionString: sisense.redshift.com user: exadmin password: expassword database: exdb permissions: viewer buildDestination: redshift